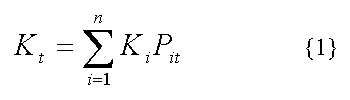ИСКЛЮЧИТЕЛЬНО ИНТЕЛЛЕКТУАЛЬНЫЕ
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ — 2
«НВС» продолжает начатый в № 10 диалог с Александром КАЗАНЦЕВЫМ о перспективах и проблемах развития важнейших для любой страны информационных технологий. С прошлого номера «НВС» остался открытым вопрос: какая судьба ждет основных создателей информационных технологий — программистов?
 |
|
Программисты появились вместе с компьютерами как интеллектуальное дополнение к ним. Говоря точнее, они — переводчики постановок решаемых на компьютерах задач с неформализованных, толком неосознанных естественных (национальных) языков на одну из самых примитивных знаковых систем — команды компьютеров. Так уж повелось, что создание абсолютно однозначных, точнейших по их результатам информационных технологий начинается с недостаточно определённых, нечётких формулировок, смысл которых их постановщики и программисты одинаково понимают не сразу, а только после использования дополнительной информации. Её никак не учитывают приверженцы мнения о неоднозначности естественных языков, указывающие в качестве доказательства своей правоты на многочисленные публикации действительно недоопределённых математических формул, например, в учебниках по вычислительной математике. При этом они в упор не замечают тех подразумеваемых данных, которые создатели информационных технологий извлекают по ассоциации с формулами из своей памяти и которыми они доопределяют первоначальные постановки формул. Не уделяют они должного внимания ещё и данным, сопровождающим сокращённо записанные формулы в виде разъяснений, дополнений, уточнений, демонстраций их действия через контрольные примеры.
Успешные действия программистов возможны только, когда они в полной мере и в совокупности осознают всю явную, косвенную и подразумеваемую информацию, заданную неформализованными выразительными средствами, определяющую задание на создаваемую ими ИТ. В какой-то мере информационное общение создателей ИТ похоже на детскую игру «Угадай-ка!», когда постановщики технологий и программисты общаются между собой обрывками сообщений, замысловатыми фразами, вынуждая друг друга очень изобретательно придумывать подходящий смысл.
Более полувека существуют компьютеры, и всё это время их пользователи не могли найти общий язык?
Увы, это так. Заказчики ИТ и их создатели хотели бы общаться на одном и том же правильно формализованном, простом в применении языке, одинаково понятном не только им, но и используемыми ими ИТ. Парадоксальность ситуации в деле создания информационных технологий в том, что столь необходимые и желаемые простейшие в использовании и исключительно выразительные средства уже давным-давно существуют, хотя у них нет ни собственного названия, ни строго определённых правил их употребления. Те, кто стараются придумать нечто более совершенное, даже не пытаются понять суть того, что уже видели многократно в публикациях по вычислительной математике и сами не один раз неосознанно использовали. Причина их неудач — в неправильной оценке сущности естественных выразительных средств, вообще, и тех, что традиционно используются при записи математических формул в частности.
Особенно фатально сказывается непонимание глобальной контекстной зависимости смысла элементов высказываний от информации, находящейся в памяти. Это неведение принципиальной особенности ЕЯ не позволяет понять роль косвенно задаваемой, а также подразумеваемой в формулах информации. Дело только за тем, чтобы понять эти выразительные средства во всём многообразии их применения и во всей их сущности.
Не углубляясь в тонкости показанной следом тривиальной в математическом аспекте и непростой в части информационного обеспечения формулы, можно определить первопричину превратного понимания ЕЯ. Она в существовании явных и не замечаемых, неявных частей описания формул.
В этой формуле Kt — это уже известное количество некоторых изделий, имеющих обозначение t. А Pit — расход другого i-го элемента на 1 изделие t. Например, если i — это шарикоподшипник, количество которого Ki = 20,
а Pit = 10 (расход t-ых шариков на одно изделие), то всего указанных t-ых шариков будет израсходовано на все i-ые подшипники 20×10=200. Суммированием всех количеств одноимённых изделий можно найти их общее число, после чего сделать разузлование этого изделия.
В автоматизированных системах управления производством формула {1} и сопутствующей ей комментарий соответствует Задаче разузлования сложных изделий и используется для расчёта количеств одноимённых элементов изделий всех механосборочных заводов.
Современные ИТ не обладают интуицией (т.е. не способны осуществлять анализ сообщений с учётом их глобального контекста), поэтому традиционные формы записи формул, аналогичных {1}, им недоступны для понимания. Однако выход всё-таки есть. Оказывается, достаточно сделать явной всю подразумеваемую и сопутствующую информацию, дополняющую постановки (формулы) любых задач, и проблемы взаимопонимания между ИТ и их пользователями станут вполне разрешимы.
§изделие¦обозначение = 'i':количество =(!Ki)
§составляющее¦обозначение = 't':расход =(!Pit);
(!Kt) = 'Ki' × 'Pit';
§изделие='t':количество=!'Ki'; {2}
Приведенная выше формула {2} — пример такой семантически достаточной формы записи. Она имеет тот же смысл, что и {1} вместе с ее комментарием, но сама в разъясняющих комментариях не нуждается. Синтаксические правила записи формулы {2} заимствованы из ЕЯ. Они семантически достаточны и могут быть использованы для первоначального отображения любых ИТ. Нет ничего проще этих правил для применения людьми и для компьютерного осуществления.
Нельзя не обратить внимание на иерархически-триадную структуру высказываний на ЕЯ. Это — последовательности иерархически упорядоченных троек лексем, первая из которых указывает тип объекта (явления). Она обозначается синтаксическим знаком, в роли которого используется символ «§» (параграф), который соответствует русскому предлогу «в», «на» и др.
Вторая в триаде лексема указывает название отличительного свойства объекта. Это —
термин, обозначаемый или символом «¦» (жирное двоеточие указывает ключевые свойства), или символом «:» (простое двоеточие — ординарное свойство).
Третья в триаде лексема представляет текущее значение свойства, указанного термином. Её отличительным знаком является символ «=».
Вновь присваиваемые обозначения в языке СОАН в соответствии с нормами ЕЯ заключаются в круглые скобки, имеющие тот же смысл, что и выражение «в дальнейшем именуемое». В обычной для ЕЯ роли используются одинарные кавычки, они соответствуют выражению «ранее названное» и др.
В естественных языках новая информация выделяется многими способами (акцентным, усиленным произношением, особыми словами). В языке СОАН для этой цели служит символ «!» (восклицательный знак).
В языке СОАН есть и другие, свойственные ЕЯ, синтаксические знаки в их обычной роли:
Ç, È, É, Ê, Ë, Ì,
Í, Î, Ï, å, Õ, ", $ и др.
Как и всякая другая область научных знаний, истинная грамматика естественных языков должна иметь свой состав аксиом, т.е. набор очевидных функционально достаточных и непротиворечивых первичных правил и понятий, из которых выводятся все остальные. В языке СОАН в этот набор входят ещё и немногие другие выразительные средства формализованного естественного языка (ФЕЯ) СОАН. СОД СОАН воспринимает их как обязательные для исполнения директивы. Определение аксиом и вывод из них грамматических правил — это углубление, совершенствование знаний, и этот процесс для ФЕЯ СОАН бесконечен.
До сих пор все попытки применения ЕЯ для строго точного информационного общения с компьютерами были безуспешны, либо неприемлемо сложны.
Это были эксперименты с утрированными подобиями ЕЯ, лишёнными самого главного их достоинства — глобальной контекстной связности элементов сообщений. СОД СОАН — единственный пример практического осуществления этого великолепного интеллектуального качества ЕЯ. Проявляется оно в том, что СОД СОАН, принимая сообщение, включает его подобно естественным интеллектам, как часть в свою память, организованную в форме семантической сети. Это включение происходит в соответствии с состоянием памяти (глобальным контекстом).
Расширяя знания СОД СОАН, корректируя собою один из её контекстов, принятое сообщение само приобретает дополнительную информацию, которой становятся ассоциируемые (контактирующие) с ним данные. Никакие другие искусственно созданные ИТ не обладают такой заимствованной у естественных интеллектов способностью понимать сообщения, обладающие одновременно предельной лаконичностью и недостижимой в других СОД информативностью.
Убедиться в практической реализации глобального контекстного анализа, казавшегося принципиально непонимаемым и нереализуемым, можно апробацией функционирования СОД СОАН. В соответствии со своим названием она способна из обрывков сообщений синтезировать их полные формы записи, используя которые она создаёт целостную базу знаний СОАН. В ней все её элементы связываются оптимальным образом причинно-следственными отношениями в глобальную сеть. Организация этой семантической сети позволяет осуществлять в ней самым простым и эффективным способом любые аналитические действия, изначально заданные не алгоритмами, а формулами на ЕЯ.
Важно отметить, что появление компьютеров, значительно ускорившее выполнение ИТ, существенно усложнило их организацию. СОД СОАН позволят выполнять информационные процессы незаслуженно забытыми и более эффективными способами, какими они осуществлялись вручную до появления компьютеров в виде информационных потоков в семантических сетях. При этом не требуется преобразование формул в алгоритмы.
Демонстрируемые СОД СОАН функции и технологии их осуществления дают основания утверждать, что достижение высочайшего искусственного интеллекта возможно только при использовании фундаментальных выразительных средств ЕЯ. Существуют убедительные доказательства интеллектуального превосходства ИТ, использующих нормально формализованные ЕЯ, над классическими их образцами в части восприятия информации в неалгоритмической, сущностной форме, т.е. без участия программистов. Более того, в такая форма обеспечивает более простую и эффективную их реализации на компьютерах.
Как вы объясните свою убеждённость в интеллектуальном превосходстве СОД СОАН над всеми другими искусственно созданными информационными технологиями?
Факты таковы, что только СОД СОАН способна по-человечески ассоциировать данные по общности их причинно-следственных связей. Эта важнейшая для каждого интеллекта операция выполняется выделением из практически безграничной памяти для каждой из лексем анализируемого сообщения всех семантически связанных (ассоциируемых) с ней лексем. Они, в свою очередь, могут стать основой для выделения лексем 3-го уровня причинно-следственных отношений и т.д. Для исполнения любого интеллектуального действия подобная локализация существенных для него данных — обязательное начало. Этому лучшим образом способствует организованная в форме семантической сети память СОД СОАН, в которой любые две лексемы или напрямую, или посредством других связаны как причины и следствия.
Статистика выполнения компьютерных команд показывает, что подавляющее их число (более 99,99%) являются подготовительными для основных операций в ИТ. По большей части они преобразуют структуры данных, а это значит, что пластичность структур данных — одно из самых важных свойств любой ИТ. В этом отношении СОД СОАН предпочтительнее всех других ИТ. Убедиться в способности СОД СОАН создавать и модифицировать самые совершенные структуры данных можно опытным путём.
Сколько времени потребует обучение использованию ФЕЯ СОАН и СОД СОАН?
Всего только 30-40 минут консультативной помощи по освоению грамматики ФЕЯ СОАН и СОД СОАН. Этого времени достаточно, чтобы показать отобранные из всех ЕЯ основные, общеизвестные выразительные средства в другом ракурсе. Образцом такой абсолютно понятной и для людей, и для ИТ грамматики является формула {2}. Менее часа после этого понадобится для создания хотя и небольшой, но показательной по своей сложности базы знаний, превосходящей по качеству известные образцы СОД.
Только СОД СОАН позволяет своим пользователям моделировать объекты и явления любой природы и сложности даже при беспорядочном и сокращённом описании их частей и свойств на языке СОАН. При этом на компьютерных носителях информации результат появляется автоматически, организованный наилучшим образом сразу же при вводе организуемых данных.
Для сравнения следует оценить муки творчества современных создателей сложных ИТ. Начинаются они с проектирования моделируемых ими объектов, реально уже существующих и потому, вроде бы, в проектировании не нуждающихся. В действительности это не проектирование, а искажённое, ненормальное изображение утрированными выразительными средствами, называемое почему-то нормализацией.
Все, кто вынужден традиционным способом закладывать искажённую информационную основу создаваемых ИТ должны смириться с мыслью, что любой сложный объект имеющимися выразительными средствами естественным целостным образом представить нельзя. Поэтому они сначала разграничивают его на части, а затем связывают их ссылками друг на друга. Каждая часть отображается реляционной матрицей, содержащей её параметры, и ссылки на другие реляционные матрицы.
Разделять, чтобы потом связывать — это не самое странное, что приходится делать при использовании современных средств системного программирования. Пытаясь обойти возникающие из-за этого проблемы, создатели реляционных БД идут на всякие ухищрения, преобразуя их в так называемые первую нормальную форму (1НФ), в 2НФ, 3НФ… и в форму Бойса-Кодда. О ненормальности этих структур данных говорит уже факт их нумерации. Ещё более ненормальными создаваемые базы данных становятся после выполнения восходящей, нисходящей, внутритабличной денормализации. Именно так называются действия по введению целесообразной(?) избыточности для предотвращения нежелательных(?) побочных эффектов.
О том, насколько проблематично создание ИТ с использованием классических инструментальных систем программирования (например, таких систем управления базами данных, как Oracle, Foxpro и др.), можно судить уже по одному только перечню терминов, смысл которых и умение пользоваться ими должен постичь каждый, кто захочет создавать ИТ известными способами. Это: сущности ассоциативные, кардинальные, пересечения, повторяющиеся внешние, промежуточные связующие, синтетические, адресные ссылки между сущностями от одного ко многим, от многих к одному, на самую себя («свиное ухо»), неисключающие подтипы и невключающие супертипы и др. непостижимые для точного понимания понятия современных технологий создания прикладных ИТ. Всего таких понятий можно насчитать более 180. Но это будет ещё неполный список вынужденно изучаемых сведений, потому что им придётся дополнительно освоить почти 100 операторов SQL, используемых уже не для организации структур данных, а для манипулирования ими.
Существенно то, что приобретение только начальных навыков создания ненормальных БД требует значительных и долговременных усилий: по крайней мере — месяц обучения на специальных курсах с отрывам от другой деятельности и 1000 $.
Значат ли ваши слова, что все используемые в ИТ формулы по вычислительной математике и другим областям знаний будут переписаны на ФЕЯ СОАН или, может быть, на каком-то другом варианте естественного языка?
Всякая наука в своём развитии приходит после очередной стадии накопления знаний к их систематизации. Целесообразность глобального обобщения всех накопленных человечеством научных знаний, необходимость выделения их квинтэссенции не вызывает сомнений. Эта задача непосильна никакому отдельно взятому человеку и даже коллективу самых талантливых учёных. Но она вполне осуществима при создании всемирной(!) базы знаний, организованной не как простое хранилище данных, а как глобальная база семантически связанной информации. Это будет всемирный проект, столь же значимый для мировой экономики, как совместно осуществляемый сейчас ведущими странами мира проект по управляемому термоядерному синтезу.
Созданный людьми и для людей этот действительно исключительный искусственный интеллект будет концентратором всех принимаемых им на ЕЯ знаний и источником фундаментальных, обобщённых знаний, возвращаемых им тоже на ЕЯ. Путь к этой цели лежит через использование нормально формализованных фундаментальных выразительных средств всех естественных (национальных) языков.
В одном из следующих номеров мы продолжим диалог с Александром Казанцевым об этой и других проблемах развития ИИИТ.
стр. 5
|