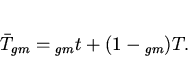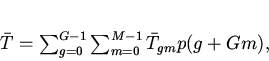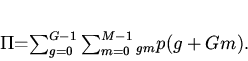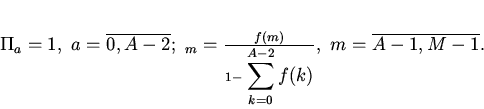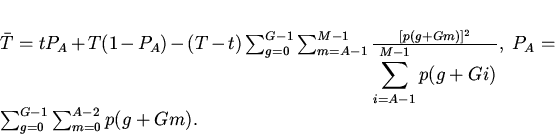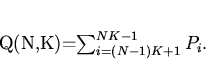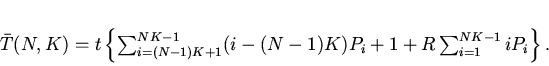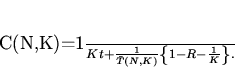Анализ эффективности ассоциативного кэша неблокирующего типа
Сущенко С.П. Томский государсвенный университет, факультет информатики
Сущенко М.С. Томский государсвенный университет информатики
Abstract:
Предложен сравнительный анализ различных моделей оранизации кэша,
позволяющий судить об их эффективности. В качестве меры эффективности
используется вероятность обнаружения в кэше нужного блока памяти при
заданных объемах кэша и памяти, размерах блока и известном распределении
приложения (кода и данных) в адресном пространстве.
Найдено среднее время выборки объекта, адресуемого приложением,
и пропускная способность многоуровневой памяти при различных параметрах кэша.
A comparative analysis of various models of cache is proposed, which allows to judge their
effectiveness. The probability of cache hit is taken as a measure of effectiveness with cache
and memory sizes given. The distribution of an application in address space and block size
are given also. Average time of retrieval of an object, addressed by an application, and memory
bandwidth are found at different cache parameters.
Введение.
В настоящее время при разработке микропроцессорных архитектур, построении
вычислительных систем и сетей, создании распределенных прикладных систем
для обеспечения быстрого доступа к наиболее часто используемым данным
широко применяется многоуровневая организация памяти.
На верхнем уровне находится самая быстрая и, как следствие, самая дорогая
и имеющая наименьший объем память в иерархии,
а на нижнем - самая медленная, дешевая и емкая
[2,3,4].
Память верхнего уровня принято называть кэшем. Функция кэширования
(накопления и сохранения данных для быстрого доступа к ним)
используется при выборе процессором
адресуемых объектов из оперативной памяти (кэш памяти), при доступе к
данным, записанным на магнитных дисках (кэш диска, размещенный в
оперативной памяти), при получении информации, распределенной во
всемирной паутине сети Internet в виде гипертекста (кэш WWW, размещенный на
локальных магнитных дисках или на магнитных носителях, существенно
приближенных к получателю информации по сравнению с основным источником).
1. Принципы функционирования ассоциативного кэша.
Идейной основой применения кэшей различных типов является принцип
пространственной и временной локальности [4].
Различают три модели организации чтения (выборки) данных из кэша:
кэш прямого отображения, полностью ассоциативный кэш и множественный
ассоциативный кэш [2].
В работе предложена общая модель, в параметрической
форме определяющая различные типы кэша.
В наиболее общем случае организации иерархической памяти
кэш и основная память разбиты на блоки (строки) длины . В кэше блоки
объединяются в группы объема , называемого коэффициентом
ассоциативности кэша. При имеем кэш прямого отображения. Если
размер группы совпадает с общим числом блоков в кэше, то получаем
полностью ассоциативный кэш. Промежуточное значение параметра
приводит к множественному ассоциативному кэшу.
На каждую -ю группу блоков кэша ассоциативности
отображается
последовательность блоков памяти с номерами
, где - количество групп кэша,
- число строк памяти, отображаемых на одну группу кэша,
и - объем кэша и памяти соответственно.
При выборе данных из кэша младшая часть адреса объекта в памяти (индекс)
однозначно определяет номер группы, в которой может быть расположен адресуемый
объект, а старшая часть, называемая признаком, используется для идентификации
требуемого блока памяти, среди множества строк памяти, отображаемых на данную
группу кэша. Для этого старшая часть адреса сравнивается с признаком,
записанным в признаковую (теговую) память каждой строки кэша при загрузке
данных. Если признак одной из строк группы совпал со старшими разрядами
адреса, то необходимая информация находится в кэше, в противном случае -
запрашиваемых данных в кэше нет и необходимо обращаться к памяти. При этом,
если все блоки группы заполнены, то возникает "конфликт адресов" блоков
памяти, отображаемых на данную группу кэша [4],
и приходится вытеснять какой-либо из блоков кэша этой группы.
Важнейшими операционными показателями кэша является
среднее время доступа к объектам кэшируемой памяти
и вероятность попадания в кэш, которые определяются прежде всего
распределением приложений по основной памяти. Данное распределение
задается вероятностями потребности вычислителя в -ом блоке
памяти, отображаемом на -ю группу кэша
.
Среднее время выбора объекта (-го блока), отображаемого на
-ю группу кэша, из двухуровневой памяти (кэш-память)
определится следующим выражением:
(1)
Здесь - вероятность обнаружения объекта в кэше,
- время выборки объекта из кэша,
- время выборки объекта из памяти.
При последовательной реализации этапов доступа к адресуемому объекту
соотношение (1) можно переписать в виде
где
- время адресации объекта в кэше,
- время сравнения признакового поля кэша со старшей частью адреса,
- среднее количество сравнений при условии обнаружения блока
в кэше,
- длина блока,
- время выборки байта из кэша,
- время вытеснения блока данных из кэша,
- время адресации объекта в памяти,
- время выборки байта из памяти и записи в кэш.
Очевидно, что среднее время доступа к объектам кэшируемой памяти
определится соотношением
(2)
а вероятность попадания в кэш - зависимостью
(3)
2. Урновая модель кэша.
Будем считать, что для группы
известны условные вероятности потребности вычислителя в
-ом блоке памяти
отображаемом на эту группу кэша. При наличии априорных сведений
только о вероятностях
процесс поиска нужного блока памяти описывается урновой моделью выбора
без возвращения [5].
Основной вопрос состоит в определении вероятности выбора
необходимого объекта за попыток.
В случае кэша произвольной ассоциативности вероятность попадания в
-ю группу -го блока памяти определится вероятностью обнаружения
его в одной из строк группы:
Условные вероятности при этом имеют вид
Условное среднее количество сравнений до обнаружения нужного блока с номером
, отображаемого на -ю группу кэша , задается
зависимостью
В случае равномерного распределения приложений по пространству адресов памяти
вероятность попадания в кэш блока памяти определится зависимостью
Отсюда видно, что при равномерном распределении приложений в памяти
вероятность попадания в кэш инвариантна к коэффициенту ассоциативности кэша.
Среднее число сравнений при этом равно
. Из чего
следует, что для приложений с равномерной загрузкой поля памяти
(частотой обращения) наилучшим является кэш прямого отображения.
Однако, как правило, реальные приложения имеют существенно неоднородное
по частоте обращения расположение адресуемых объектов в оперативной памяти.
3. Модель кэша с идеальным вытеснением блоков.
Важнейшим фактором, определяющим частоту попадания в кэш ассоциативности
, является стратегия
вытеснения блоков из группы кэша при возникновении конфликта адресов.
Очевидно, что наиболее предпочтительной является стратегия вытеснения самого
неиспользуемого блока в группе, т.е. имеющего наименьшую вероятность
быть востребованным.
Определим влияние оптимальной стратегии вытеснения самого неиспользуемого
блока в группе на общую производительность кэша (частоту попадания в кэш).
Для простоты будем анализировать отдельную группу кэша и при рассмотрении
опустим индекс принадлежности к различным группам кэша .
Предположим, что вероятности упорядочены
по убыванию значений и априори известны механизму вытеснения блоков кэша.
Функционирование группы кэша можно описать случайным Марковским процессом
в -мерном пространстве
, где - номер блока
памяти, находящегося в -м блоке группы кэша. Переходные вероятности
цепи Маркова, описывающей динамику процесса замещения блоков данных в кэше
имеют вид перемещений вдоль координатной оси с максимальным значением
координаты:
Здесь и - координаты исходного и измененного состояний
соответственно.
Рассмотрим кэш ассоциативности, равной двум. В стационарных условиях
уравнения равновесия для вероятностей состояния полностью
заполненной группы кэша принимают вид
С учетом условия нормировки
отсюда находим, что вероятные состояния
симметричны и расположены вдоль координатных осей:
Вероятность попадания в кэш буфера с номером
определится соотношением:
С учетом вида вероятностей состояний отсюда получаем:
То есть самый используемый блок (с номером ) в стационарном
режиме всегда находится в кэше.
Пусть . Тогда уравнения равновесия записываются следующим образом:
Для вероятностей состояния справедливо:
Вероятности обнаружения необходимых блоков памяти в кэше определяются
из выражения
Из данного соотношения окончательно получаем:
Отсюда следует, что при ассоциативности два самых используемых блока
памяти, отображаемых на данную группу, гарантированно находятся в кэше.
Для кэша произвольной ассоциативности система уравнений равновесия
принимает следующий вид:
а вероятные состояния симметричны и находятся на отрезках прямых, параллельных
различным координатным осям, общее количество которых равно числу перестановок
координат:
Таким образом, цепь Маркова, описывающая динамику вытеснения блоков кэша,
распадается на совокупность замкнутых множеств состояний, образующих
неприводимых подцепей Маркова [1].
Для вероятностей обнаружения блоков памяти в кэше в силу симметричности
вероятностей состояний цепи Маркова справедливо:
При этом
(4)
Отсюда следует, что строк кэша
достоверно содержат самые необходимые блоки памяти, а строк
(по одной в каждой группе) используются для попеременной подкачки недостающих
вычислителю блоков памяти. Из чего можно заключить, что вероятность попадания
в кэш (3)
принимает максимальное значение при полностью ассоциативном
кэше, в котором только одна строка используется для замещения блоков памяти
в то время как в других находится самая востребованная процессором информация.
В силу симметричности вероятностей состояний условное среднее
число сравнений признакового поля кэша с признаком, выделенным из адреса
объекта, для любого составляет
Рассмотренная схема вытеснения основана на априорном знании вероятностей
. В реальной ситуации эти показатели заранее неизвестны, а
оцениваются по количеству обращений программ к различным блокам группы кэша.
4. Динамические свойства идеального кэша.
Поскольку при выполнении вычислительых процессов из-за динамики вычислений и
перемещения страниц виртуальной памяти в общем случае распределение
приложений в памяти изменяется, то важными параметрами кэша
являются вероятностно-временные характеристики движения
Марковского процесса замещения блоков кэша к стационарному состоянию.
Найдем функцию вероятностей
, распределение времени
движения к стационарному состоянию
и среднее время
в течение которого из любого нестационарного состояния
можно попасть в одну из неприводимых подцепей Маркова.
Время движения к стационарному состоянию - это время попадания
координат цепи Маркова в область значений пространства состояний
.
При время движения распределено по
геометрическому закону с параметром и
среднее время определяется соотношением
.
С ростом ассоциативности геометрический характер функции вероятностей
сохраняется, но по мере достижения координат стационарного состояния
меняется параметр распределения.
Для кэша ассоциативности вероятность
достижения стационарного состояния ровно за шагов сначала имеет
геометрический вид с вероятностью неуспеха, равной , и
вероятностями успеха и событий и
соответственно. После попадания в
состояние или параметр распределения принимает значение
или соответственно. Определение функции вероятностей
имеет вид:
Вероятность достижения стационарного состояния за время
задается зависимостью
а среднее время движения к стационарному состоянию составит:
В случае отсюда получаем
.
Для произвольного функция вероятностей определится следующим
соотношением:
При
вероятностно-временные
характеристики переходных процессов функционирования кэша принимают вид:
Анализ среднего времени движения к стационарному состоянию показывает, что
минимальное значение при ограничении
достигается для однородных вероятностей потребности
.
5. Анализ времени доступа.
В силу предположения об упорядоченности вероятностей , а
следовательно и , внутри групп кэша по убыванию, для
среднего времени выбора адресуемых объектов (2) при идеальном
вытеснении с учетом (4) справедливо
(5)
Здесь имеет смысл доли распределения востребованных данных,
расположенных в блоках всех групп кэша, и характеризует степень
локализации кода программ и данных в кэше. Нетрудно видеть, что с
ростом емкости и ассоциативности кэша доля растет.
Рост вероятностной массы имеет место и в случае увеличения
вероятностей для
.
Среднее время доступа принимает максимальное значение для равномерного
распределения
:
Величина при этом имеет минимальное значение
Минимальное время доступа
достигается тогда, когда все
востребованные данные размещаются в кэше, то есть либо , либо
, но
.
В том случае, если равномерно распределен "хвост" распределения
среднее время выборки адресуемого объекта линейно падает с ростом
локализации приложения в кэще :
Для распределения "хвоста" в отдельных группах кэша в виде однородных
треугольников (арифметических прогрессий) при
Область допустимых значений степени локализации при этом имеет вид:
. Численные исследования
показывают, что среднее время доступа к адресуемым объектам (5)
слабо зависит от вида "хвоста" распределения
.
6. Модель кэша неблокирующего типа.
Процесс функционирования многоуровневой памяти с кэшем неблокирующего типа
может быть описан работой двухстадийного конвейера. На первой фазе конвейера
выполняется обращение к кэш-памяти. Длительность этой фазы равна времени
доступа к кэшу t. При попадании адресуемого объекта в кэш выполняется
следующий запрос к иерархической памяти. В случае промаха одновременно
происходит обработка текущего запроса на второй фазе - фазе доступа к
оперативной памяти и следующей транзакции - на первой фазе.
Таким образом, факт обработки транзакции доступа к иерархической памяти на
второй фазе является случайным событием.
Время обработки транзакции на второй фазе в раз превышает
время обращения к кэш-памяти . При глубине неблокируемости
подсистема многоуровневой памяти имеет буфер емкости для хранения
запросов к оперативной памяти, которые последовательно обрабатываются
элементами управления памятью на второй фазе конвейера. Если количество
таранзакций, обрабатываемых в фазе обращения к оперативной памяти,
совпадает с , то кэш-память оказывается заблокированной.
В заблокированном состоянии первая стадия конвейера не работает.
Разблокирование первой фазы наступает при завершении обработки одной
транзакции на второй фазе конвейера.
Для описания процесса обработки запросов к двухуровневой памяти с глубиной
блокировки, равной , будем
моделировать стадию доступа к оперативной памяти
Марковской системой масового обслуживания (СМО) с дискретным временем и
-этапным обслуживающим прибором [1]. Длительность цикла
дискретной СМО составляет время . Время между поступлениями заявок
(транзакций обращения к оперативной памяти) кратно и имеет
геометрическое распределение с параметром, равным вероятности промаха .
Считаем, что доступ к многоуровневой
памяти выполняется только на чтение или только на запись.
Будем полагать, что в каждом такте выполняется обращение к кэш-памяти
(при незаблокированной первой фазе конвейера) и
с вероятностью промаха в СМО поcтупает заявка с временем обработки
, равным трудоемкости выполнения этапов СМО длительности .
Поскольку обработка различных запросов к оперативной и кэш-памяти выполняется
параллельно, то цепь Маркова, описывающая динамику количества этапов обработки
совокупности заявок на доступ к оперативной памяти будет содержать
состояний. Заблокированным соответствует множество состояний
.
Переходные вероятности цепи Маркова имеют вид:
Система уравнений равновесия для стационарного режима функционирования
дискретной СМО, описывающей процесс доступа к иерархической памяти,
для произвольной глубины
неблокируемости и целочисленного отношения времен обращения к
оперативной памяти и кэш-памяти записывается следующим образом:
Важнейшими операционными характеристиками иерархической памяти являются
вероятность блокировки кэш-памяти, среднее время доступа и пропускная
способность.
Вероятность блокировки определяется суммой вероятностей состояний, в которых
на фазе доступа к оперативной памяти (в СМО) выполняется обработка
транзакций:
(6)
Среднее время доступа к адресуемым объектам складывается из
времени разблокирования кэш-памяти, времени обращения к кэшу и времени
обращения к оперативной памяти (при промахе в кэш):
(7)
Пропускная способность определяется
количеством транзакций доступа к многоуровневой памяти, обработанных за время
:
С учетом (7) данное определение можно переписать в виде:
(8)
Анализ показывает, что при заданной вероятности промаха в кэш-памяти
пропущенный по системной шине поток транзакций доступа к адресуемым
объектам оперативной памяти (8)
растет с увеличением глубины неблокируемости,
а среднее время выборки операндов и команд из иерархической памяти
(7) и вероятность блокировки (6) - падают.
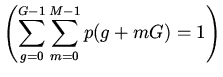 .
Среднее время выбора объекта (
.
Среднее время выбора объекта (
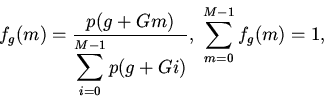
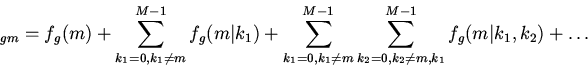
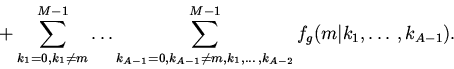
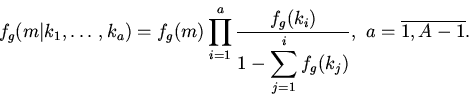
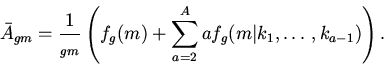
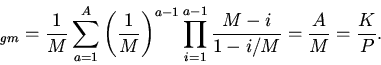
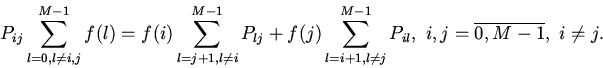
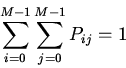
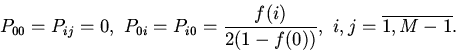
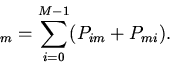
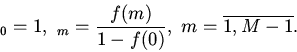
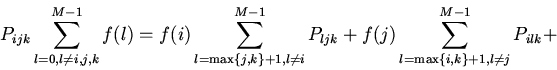
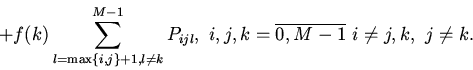
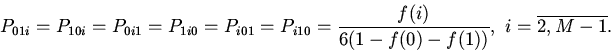
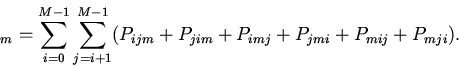
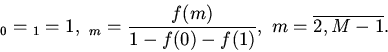
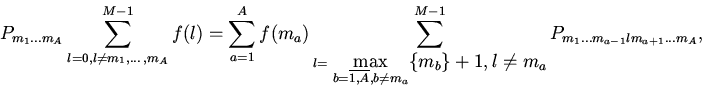
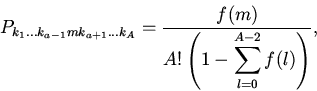
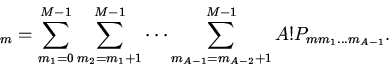
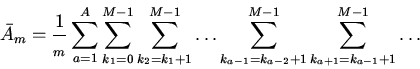
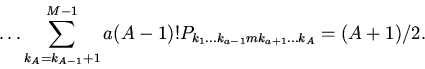
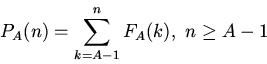
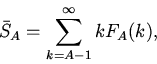
![\begin{displaymath}
F_3(k)=f(0)f(1)\sum_{i=0}^{k-2}
[1-f(0)-f(1)]^i\{[1-f(0)]^{k-i-2}+[1-f(1)]^{k-i-2}\}=
\end{displaymath}](img89.gif)
![\begin{displaymath}
\bar{S}_3=\frac{f^3(0)+f^3(1)+2f(0)f^2(1)+2f^2(0)f(1)}{f(0)f(1)[f(0)+f(1)]^2}.
\end{displaymath}](img93.gif)
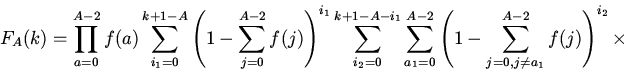
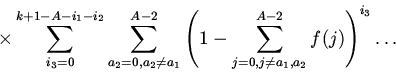

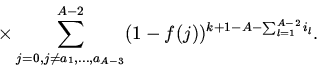
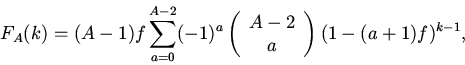
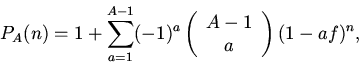
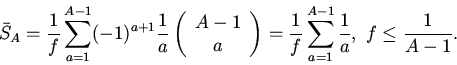
 достигается для однородных вероятностей потребности
достигается для однородных вероятностей потребности
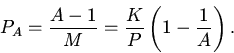
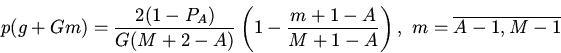
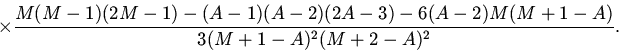
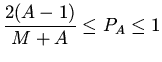 . Численные исследования
показывают, что среднее время доступа к адресуемым объектам (5)
слабо зависит от вида "хвоста" распределения
. Численные исследования
показывают, что среднее время доступа к адресуемым объектам (5)
слабо зависит от вида "хвоста" распределения
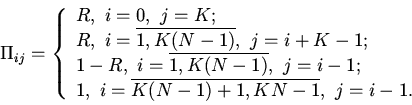
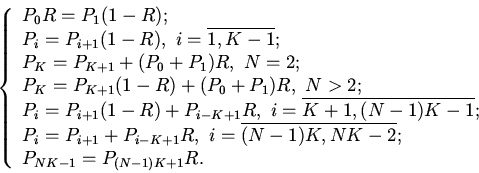
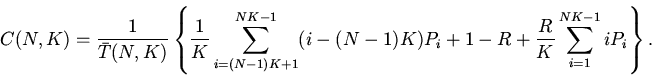
 Ваши комментарии
Ваши комментарии
![[SBRAS]](/gif/s_sigma.gif)