Гадицкий Р.В. Новосибирский государственный университет
Аннотация:
The problem of information analysis is considered.
As practice shows, it often happens that
we have no access to whole data being under analysis at once,
but it can be only received step by step.
In this case we have two approaches.
The first is to wait until all data is received and
then proceed with analysis.
The second is to begin the analysis while data is coming.
In this paper we consider the idea of using agent-based
technologies to problems, which allow applying of the second approach.
The paper also contains an example of natural language analysis.
Рассматривается задача анализа информации.
На практике часто бывает так, что данные, которые необходимо проанализировать, не доступны
все сразу, а поступают последовательно, порциями.
Для анализа подобного рода последовательно поступающей информации возможны два подхода.
Первый состоит в том, чтобы ожидать, пока интересующая нас информация поступит в полном
объеме,
аккумулировать ее, и только затем приступать к ее обработке.
Второй подход заключается в попытке производить
анализ информации в процессе ее поступления.
Для решения задачи, позволяющей применять второй подход,
предлагается использовать парадигму агентно-ориентированного программирования.
Приведен пример применения данного подхода для
автоматического понимания естественно-языковых текстов.
Для искусственного интеллекта задача анализа информации является классической. Эта задача
в общем случае состоит в том, чтобы осуществить отображение из некоторого множества входных
данных во множество выходов, представляющих собой результаты анализа. К таким задачам
относятся, например, задача распознавания видеоизображений, звуковых образов, анализ
естественно-языковых текстов и т.д. На практике часто бывает так, что данные, которые
необходимо проанализировать, не доступны все сразу, а поступают последовательно, порциями.
Такая ситуация может иметь место, если речь идет, например, о каком-либо процессе или объекте
исследования, информация о которых поступает в реальном времени. Для анализа подобного рода
последовательно поступающей информации возможны два подхода. Первый состоит в том, чтобы
ожидать, пока интересующая нас информация поступит в полном объеме, аккумулировать ее, и
только затем приступать к ее обработке. Второй подход заключается в попытке производить анализ
информации в процессе ее поступления. В ряде случаев оказывается удобнее применять второй
подход, так как он может иметь некоторые преимущества. Во-первых, использование второго
подхода дает возможность начать анализ процесса до его окончания и принимать оперативные
решения на основании уже полученной информации. Во-вторых, это может повысить эффективность
анализа, так как не будет "периода ожидания", как в первом подходе.
При использовании второго подхода возникает проблема обработки данных в условиях
недоопределенности, когда информации недостаточно, чтобы провести анализ. Здесь следует отметить,
что для человека является естественным получать информацию последовательно, например так
происходит при восприятии речи, читке текстов, просмотре видео и т.д. Исследования в области
психологии познания и мышления показывают, что человек анализирует информацию непосредственно в
процессе восприятия, то есть "в реальном времени". Известно также, что при этом он склонен к
прогнозированию свойств объектов восприятия.[1,2] В связи с этим представляется необходимой
разработка средств для реализации подобных механизмов анализа на ЭВМ.
В работе описан подход к анализу последовательно поступающей информации, использующий парадигму
агентно-ориентированного программирования. В данном подходе мультиагентная система, являющаяся
субъектом анализа, реагирует на поступающие данные и на основании их анализа прогнозирует
возможное будущее содержание еще не поступившей информации. В работе также приведен пример
применения данного подхода для автоматического понимания естественно-языковых текстов.
Прежде всего дадим некоторые определения и сформулируем предметную область, в которой будет
осуществляться дальнейшее рассмотрение.
Как уже говорилось, мы рассматриваем задачу анализа информации. Постановка задачи в самом общем
виде выглядит следующим образом. Предположим, что существует некоторое множество . В качестве
информации, подлежащей анализу, будем рассматривать произвольную совокупность элементов из .
Каждый элемент представляет собой наименьшую порцию информации, которая может поступить за один
раз. Предположим, что существует отношение между множеством подмножеств и некоторым множеством
такое, что
. Элементы будем называть результатами анализа. Так как
анализ производится на ЭВМ, то естественно предположить, что существует некоторый алгоритм ,
посредством которого осуществляется построение на основе данного . В этом случае имеем
.
Последовательно поступающая информация рассматривается нами как цепочка вложенных подмножеств
. В связи с этим возникает два вопроса. Первый
вопрос: существует ли для каждого
такое, что
? Если
такое bi существует, то это значит, что существует некоторый алгоритм строящий по
. Второй вопрос: можно ли использовать для построения ? Мы будем рассматривать тот
случай, когда на оба вопроса можно дать положительный ответ, и более того, состоит из
последовательности . Здесь важно отметить, что на каждом шаге может существовать несколько
и, соответственно, несколько . Таким образом, при получении очередного мы имеем
дело с несколькими гипотезами, состоящими в выборе того или иного для формирования
результирующего . Позже мы можем отказаться от некоторых из гипотез, как противоречащих
информации, поступившей после их выдвижения и не позволяющих производить дальнейшее построение .
После получения всего а мы будем иметь одну или, возможно, несколько гипотез. Здесь мы
предполагаем, что любая из них нам подходит. Теперь мы рассмотрим
мультиагентную систему, позволяющую строить алгоритм указанным
образом.
Дадим сначала краткое определение агента, которое будет использовано нами при построении
мультиагентной системы. Его схематическое изображение представлено на Рис.1.
Рис. 1.
Схема агента.
Агент обладает рецептором, который позволяет ему реагировать на изменение во внешней среде.
Рецептор представляет собой некоторое утверждение о внешнем мире. После того как это утверждение
становится истинным, агент выполняет некоторые действия, в соответствие с окружающей средой и его
памятью. Эти действия определяются активной частью агента. Агенты могут создавать, удалять,
активировать и дезактивировать друг друга. (Агент в дезактивированном состоянии ничего не делает,
но существует и способен быть активирован вновь).
Предлагаемый подход состоит в том, чтобы в процессе поступления строить систему агентов.
Каждый агент, входящий в систему, имеет рецептор, направленный на поступление новой информации.
Он также хранит в своей памяти различные составляющие алгоритма и список агентов,
созданных этим агентом. Активные части агентов содержат стратегии генерации гипотез. Сеть агентов
строится следующим образом. Первоначально сеть состоит из одного агента. После поступления
он создает ряд агентов, каждый из которых, соответствует гипотезе о поступлении . После этого
первый агент, отработав, дезактивирует сам себя. Все созданные им агенты действуют аналогичным
образом. Таким образом, при поступлении каждого мы имеем ряд активных агентов
соответствующих ряду рабочих на данный момент гипотез. Поднимаясь от первого агента к каждому из
активных агентов, пробегая все предшествующие ему дезактивированные агенты, мы можем получить
алгоритм построения одного из предполагаемых . После получения всего а таким же образом можно
получить и, следовательно, .
Рассмотрим простой пример, иллюстрирующий работу описанного
подхода.
Рассматривается абстрактный робот, находящийся в некотором окружении видимых для него объектов.
Требуется преобразовать предложение, являющееся формулировкой некоторого требования к роботу на
естественном языке, в некоторое внутренне представление. Вот некоторые примеры входных
предложений:
Найди стол и принеси его в 4-ю комнату.Принеси зеленый и красный стулья из комнаты номер 3 в 1-ю
комнату.
Предложение поступает в виде семантической сети, представляющей собой цепочку лексем. В
процессе ввода предложения лексемы добавляются в конец цепочки. Таким образом, мы имеем
последовательно поступающую информацию. Множеством в данном случае будет множество
воспринимаемых анализатором слов.
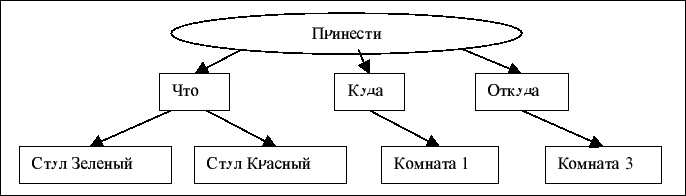
Внутренне представление семантики предложения ищется в виде семантической сети. Например, второму
предложению будет соответствовать сеть, изображенная на Рис.2.
Рис. 2.
Пример
семантической сети, отражающей смысл предложения.
Построение подобной сети легко выполнить при помощи продукционных правил, дождавшись ввода
предложения целиком. Такое построение будет связано с поиском по образцу и, следовательно,
перебором. Чтобы избежать перебора и начать строить сеть уже в процессе ввода предложения можно
применить описанный подход.
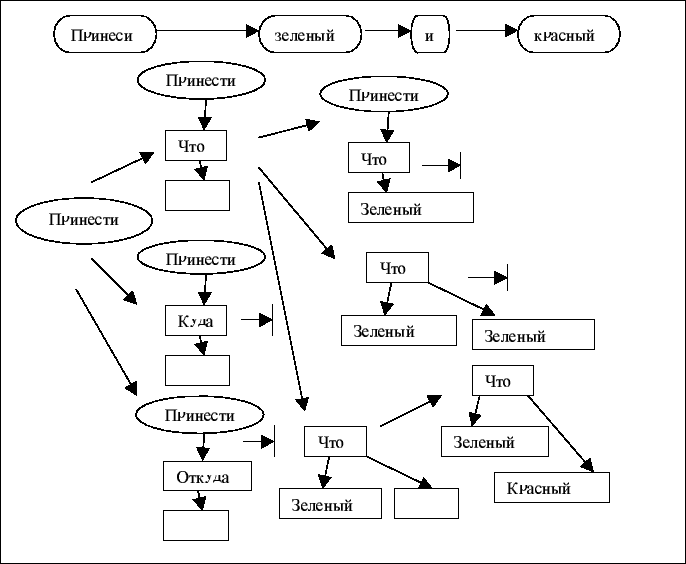
С получением каждой лексемы генерируются агенты, соответствующие гипотезам дальнейшего построения
семантической сети, отражающей смысл вводимого предложения. Каждый агент содержит информацию,
являющуюся очередным шагом в построении этой сети, а также заключает в себе правило генерации
новых гипотез, если они не вступят в противоречие с последующей лексемой, и самоудаления в
противном случае. В любой момент можно построить сеть по данным, накопленным в памяти агентов.
Часть разбора второго предложения из примера иллюстрирована на Рис.3.
Безусловно, данный метод применим лишь к узкой области задач. Но с его помощью уже можно увидеть
преимущества реактивного подхода, такие как повышение эффективности анализа информации и
возможность получения промежуточных результатов при анализе недоопределенной информации. Данная
работа также расширяет область применения агентных технологий. В настоящее время ведется работа
над созданием агентно-ориентированной среды программирования [3] и экспериментальное исследование
поведения мултиагентных систем, в частности описанного метода. В качестве перспективы дальнейшей
работы предполагается модернизация его с целью анализа больших текстов, где указанные преимущества
проявятся в полной мере.
Zagorulko Yu.A., Popov I.G. Knowledge representation language based
on the integration of production rules, frames and a subdefinite
model //
Joint Bulletin of the Novosibirsk Computing Center and Institute of Informatics Systems.
Series: Computer Science, 8 (1998), NCC Publisher, - Novosibirsk, 1998.
-P.81-100.


 Ваши комментарии
Ваши комментарии
![[SBRAS]](/gif/s_sigma.gif)