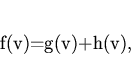Костюк Ю.Л.
Томский государственный университет
Новиков Ю.Л.
НПО "Сибгеоинформатика''
During first vectorization stage, when individual liear segments
of different colour lines are recognized automatically, as well as filled
regions, we suggest building primary graph model on them, represented
in the triangulation form. On it's base objects graph model is built
interactively, consisting of two layers: the first layer is formed
of filled regions and the second (top) layer consists of entirely
recognized broken lines and contours. The applying of triangulation allows
to build objects graph model by more time-effective algorithms and reduce
occurence number of user interference into the algorithms functioning.
Чаще всего ограничиваются рассмотрением наиболее простых элементов изображения, а именно ломаных, составленных из прямолинейных отрезков, причем допускается сочленение нескольких отрезков в одной точке. При этом каждому отрезку (или всей ломаной) приписывается характеристика толщины (в пикселях). Задача векторизации при этом решается в два этапа. На этапе первичной векторизации строится граф из множества распознанных на растре прямолинейных отрезков. На втором этапе -- объектной векторизации -- из отрезков составляются ломаные линии, многоугольники и другие фигуры, при этом обычно требуется вмешательство человека [8,9].
Структура данных (граф), формируемая на этапе первичной векторизации, должна быть наиболее удобной для работы алгоритмов объектной векторизации. Известные графовые модели, например описанные в [5,8,9], являются планарными графами линий (ПГЛ), в которых все ребра суть прямолинейные отрезки, а вершины -- точки на плоскости, являющиеся концами отрезков или точками сочленения нескольких отрезков. Заметим, что в ПГЛ ребра не пересекаются между собой.
Для формирования такой модели обычо вначале выделяют скелетное изображение, или просто скелет, который представляет собой набор осевых линий единичной толщины (в один пиксель), проведенных внутри исходных линий (как толстых, так и тонких).
Скелет по Розенфельду [6] строится следующим образом.
Вначале для каждого черного пикселя изображения вычисляется вес --
расстояние до ближайшего фонового пикселя. Затем выделяются пиксели с
максимальным значением индекса и соединяются между собой отрезками,
проходящими через закрашенные участки изображения. Кроме того, для
каждого отрезка вычисляется харктеристика толщины. Такой алгоритм
требует многократного просмотра всего растрового изображения, при этом
каждый просмотр имеет трудоемкость ![]() .
.
Этим алгоритмом можно обрабатывать изображение, содержащее пиксели нескольких различных цветов. Для этого предварительно для каждого цвета (кроме одного -- фона) выделяются пиксели этого цвета, а все остальные считаются фоновыми. Полученные после векторизации отдельные цветные линии можно объединить в одну общую графовую модель.
Если в исходном изображении наряду с линиями могут присутствовать также закрашенные области, то корректно выделить их рассмотренным алгоритмом не удается. Кроме того, при этом требуется расширение графовой модели изображения.
В общем случае, если растр содержит более двух цветов, то можно считать, что он состоит только из непересекающихся изображений линий и закрашенных областей, и не содержит фоновых пикселей. При этом предполагается, что весь растр окружен пикселями особого (нулевого) цвета, отсутствующего внутри изображения. Предполагается также, что изображение не содержит "шумов'' -- случайных пикселей, окрашенных в случайные цвета. (Некоторые из таких пикселей могут быть обнаружены и их цвет откорректирован либо путем предварительной фильтрации изображения, либо после построения графовой модели на этапе объектной векторизации.)
Для корректного моделирования ![]() -цветных растров предлагается
полигонально-линейная
графовая модель (ПЛГМ), которая определяется как четверка множеств:
-цветных растров предлагается
полигонально-линейная
графовая модель (ПЛГМ), которая определяется как четверка множеств:
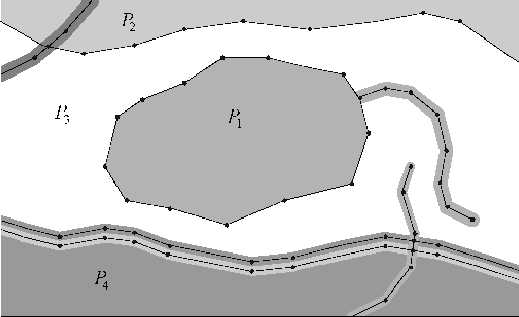
Предполагается также, что все точки имеют различающиеся на плоскости координаты, и никакие из двух ребер не пересекаются друг с другом при их их изображении на плоскости. На рис. 1 показан пример наложения ПЛГМ на исходный растр.
Рассмотрим построение ПЛГМ. На первом этапе выделим линии, определим для них характеристики (толщину, цвет), а также выделим границы между закрашенными областями.
Алгоритм построения графа линий.
1. Для многоцветного растрового изображения ![]() один из
один из ![]() цветов (который
использован на изображении только для закраски областей, но не линий)
объявляется фоновым, остальные
цветов (который
использован на изображении только для закраски областей, но не линий)
объявляется фоновым, остальные ![]() цветов -- базовыми.
цветов -- базовыми.
2. Создаем растр ![]() , имеющий размеры исходного растра, с нулевыми
значениями пикселей.
, имеющий размеры исходного растра, с нулевыми
значениями пикселей.
3. Цикл по ![]() базовым цветам. Пусть
базовым цветам. Пусть ![]() -- текущий цвет.
-- текущий цвет.
3.1. Из исходного растрового изображения ![]() получение бинарного
изображения
получение бинарного
изображения ![]() относительно текущего цвета
относительно текущего цвета ![]() : для пикселей с цветом
: для пикселей с цветом ![]() записывается 1, для других -- 0.
записывается 1, для других -- 0.
3.2. Из растрового изображения ![]() получение изображения
получение изображения ![]() , в котором
каждый пиксель содержит значение целочисленного 4-связного расстояния
до ближайшего фонового пикселя. Эффективные алгоритмы нахождения таких
изображений см. в работе [8].
, в котором
каждый пиксель содержит значение целочисленного 4-связного расстояния
до ближайшего фонового пикселя. Эффективные алгоритмы нахождения таких
изображений см. в работе [8].
3.3. Из растрового изображения ![]() построение скелетного изображения
построение скелетного изображения
![]() , которое содержит только скелетные линии, то есть линии
единичной толщины, проходящие по серединам объектов на растре
, которое содержит только скелетные линии, то есть линии
единичной толщины, проходящие по серединам объектов на растре ![]() .
Эффективный алгоритм для решения этой задачи предложен одним из авторов
в [4].
.
Эффективный алгоритм для решения этой задачи предложен одним из авторов
в [4].
3.4. Из растрового изображения ![]() и скелетного изображения
и скелетного изображения
![]() построение изображения "расстояние от скелета''
построение изображения "расстояние от скелета'' ![]() , в котором
каждый ненулевой пиксель принимает значение расстояния от него до ближайшего
скелетного пикселя. Эффективный алгоритм для этого предложен одним из авторов
в [3].
, в котором
каждый ненулевой пиксель принимает значение расстояния от него до ближайшего
скелетного пикселя. Эффективный алгоритм для этого предложен одним из авторов
в [3].
3.5. Вычисление растрового изображения ![]() . В результате пиксели
растра
. В результате пиксели
растра ![]() будут содержать значения
целочисленной 4-связной толщины растровых объектов в данных пикселах.
Фоновые пиксели растра
будут содержать значения
целочисленной 4-связной толщины растровых объектов в данных пикселах.
Фоновые пиксели растра ![]() по-прежнему будут содержать 0.
по-прежнему будут содержать 0.
3.6. Разложение растра ![]() на два растра:
на два растра: ![]() (линейные объекты)
и
(линейные объекты)
и ![]() (закрашенные области). Ненулевые пиксели
из
(закрашенные области). Ненулевые пиксели
из ![]() , значение которых меньше
, значение которых меньше ![]() , переносятся в
, переносятся в ![]() , остальные
ненулевые пиксели -- в
, остальные
ненулевые пиксели -- в ![]() .
.
3.7. В растровое изображение ![]() добавление ненулевых пикселей из
добавление ненулевых пикселей из ![]() и тех нулевых пикселей из
и тех нулевых пикселей из ![]() , которые в своей 8-окрестности граничат
с ненулевыми пикселями. Пикселям из
, которые в своей 8-окрестности граничат
с ненулевыми пикселями. Пикселям из ![]() приписывается цвет
приписывается цвет ![]() , а
пикселям из
, а
пикселям из ![]() -- цвет
-- цвет ![]() . При этом пиксель из
. При этом пиксель из ![]() может
замещать пиксель с цветом 0 или
может
замещать пиксель с цветом 0 или ![]() , а пиксель из
, а пиксель из ![]() -- только
пиксель с цветом 0.
-- только
пиксель с цветом 0.
4. Скелетизация изображения ![]() с получением растрового изображения
с получением растрового изображения ![]() .
При скелетизации все ненулевые пиксели интерпретируются как объектные,
а нулевые -- как фоновые. Полученный обобщенный скелет моделирует линии
толщиной меньше
.
При скелетизации все ненулевые пиксели интерпретируются как объектные,
а нулевые -- как фоновые. Полученный обобщенный скелет моделирует линии
толщиной меньше ![]() и границы между закрашенными областями
на исходном изображении.
и границы между закрашенными областями
на исходном изображении.
5. Построение графа линий ![]() по обобщенному скелету
по обобщенному скелету ![]() . Для этого
применяется алгоритм отслеживания скелетных линий и построения векторных
ломаных по ним, описанный в работе [9].
. Для этого
применяется алгоритм отслеживания скелетных линий и построения векторных
ломаных по ним, описанный в работе [9].
При этом для ребер, которые соответствуют линейным объектам на растре,
приписываются характеристики толщины и цвета, такие ребра образуют
множество ![]() . Остальные ребра из
. Остальные ребра из ![]() соответствуют границам между
закрашенными областями на растре и образуют множество
соответствуют границам между
закрашенными областями на растре и образуют множество ![]() .
.
Конец алгоритма.
Выполняемое в п. 3.7 алгоритма добавление нулевых пикселей из ![]() в растровое изображение
в растровое изображение ![]() формирует границы между двумя закрашенными
в различные цвета областями. Если же закрашенная область ограничена
линией другого цвета, то эта линия и будет служить границей в
формирует границы между двумя закрашенными
в различные цвета областями. Если же закрашенная область ограничена
линией другого цвета, то эта линия и будет служить границей в ![]() ,
никакой дополнительной границы не появится.
,
никакой дополнительной границы не появится.
После работы алгоритма для завершения построения ПЛГМ остается
выделить множество полигонов ![]() .
.
1. По границе прямоугольной области векторизации построим прямоугольник.
2. Добавим внутрь области отрезки множества ![]() , которые не
пересекаются между собой, но могут сочленяться концами в некоторых точках.
, которые не
пересекаются между собой, но могут сочленяться концами в некоторых точках.
3. Добавим внутрь области дополнительные невидимые отрезки, которые не
пересекаются ни с отрезками множества ![]() , ни между собой и делят всю
прямоугольную область на треугольники. Эти отрезки образуют множество
, ни между собой и делят всю
прямоугольную область на треугольники. Эти отрезки образуют множество ![]() .
.
Если ![]() -- количество точек концов отрезков, то количество треугольников
в построенной триангуляции несколько меньше
-- количество точек концов отрезков, то количество треугольников
в построенной триангуляции несколько меньше ![]() . В общем случае количество
различных триангуляций, которые могут быть построены на одном и том же
множестве точек или отрезков очень велико. Если триангуляция строится
на множестве точек, то наиболее эффективной ее разновидностью
является триангуляция Делоне [5], содержащая треугольники,
наиболее близкие к равносторонним. В то же время триангуляция с
ограничениями, построенная
на множестве ребер, может быть как угодно далека от триангуляции Делоне.
. В общем случае количество
различных триангуляций, которые могут быть построены на одном и том же
множестве точек или отрезков очень велико. Если триангуляция строится
на множестве точек, то наиболее эффективной ее разновидностью
является триангуляция Делоне [5], содержащая треугольники,
наиболее близкие к равносторонним. В то же время триангуляция с
ограничениями, построенная
на множестве ребер, может быть как угодно далека от триангуляции Делоне.
В [5] приведен алгоритм построения случайной триангуляции
с ограничениями за гарантированное время ![]() , а в
[10,11] -- алгоритм построения триангуляции с
ограничениями, наиболее близкой к триангуляции Делоне, за среднее
время
, а в
[10,11] -- алгоритм построения триангуляции с
ограничениями, наиболее близкой к триангуляции Делоне, за среднее
время ![]() . Второй из алгоритмов в процессе триангуляции создает и
использует вспомогательную кэш-таблицу, позволяющую быстро (в среднем
за константное время) по координатам произвольной точки определить
треугольник, внутрь которого она попадает.
. Второй из алгоритмов в процессе триангуляции создает и
использует вспомогательную кэш-таблицу, позволяющую быстро (в среднем
за константное время) по координатам произвольной точки определить
треугольник, внутрь которого она попадает.
Структура триангуляции ![]() содержит массив треугольников, каждый треугольник
в которой имеет ссылки на точки и/или на ребра, его образующие, а также
ссылки на три соседних треугольника. Таким образом, за один шаг можно
от одного треугольника перейти к смежному треугольнику.
содержит массив треугольников, каждый треугольник
в которой имеет ссылки на точки и/или на ребра, его образующие, а также
ссылки на три соседних треугольника. Таким образом, за один шаг можно
от одного треугольника перейти к смежному треугольнику.
После построения триангуляции можно произвести классификацию треугольников -- объединение их в такие группы, что треугольники внутри одной группы разделены между собой невидимыми ребрами. Ясно, что каждая такая группа образует сплошную область, закрашенную одним цветом, кроме, может быть, кромок отдельных треугольников, лежащих на краю области. (Такие кромки соответствуют линиям некоторой толщины, ограничивающим область.)
Классификацию треугольников легко выполнить алгоритмом, аналогичным алгоритму попиксельной закраски сплошных площадей [7]. После выделения очередной группы треугольников этой группе необходимо приписать цвет закраски. Его можно взять из исходного растрового изображения, как наиболее часто встречающийся внутри выделенной области.
В процессе классификации, после выделения очередной группы треугольников,
необходимо сформироровать полигон (границу области) и добавить его в
множество ![]() . Границу области можно отследить, последовательно переходя
к смежным треугольникам. Если область простая, т.е. имеет одну границу,
то остается определить получившийся при отслеживании вариант обхода:
по часовой стрелке или против часовой стрелки. Это легко сделать,
определив крайнюю точку границы (например, с максимальной по
. Границу области можно отследить, последовательно переходя
к смежным треугольникам. Если область простая, т.е. имеет одну границу,
то остается определить получившийся при отслеживании вариант обхода:
по часовой стрелке или против часовой стрелки. Это легко сделать,
определив крайнюю точку границы (например, с максимальной по ![]() координатой).
координатой).
Если же область сложная, т.е. имеет "дыры'', то их все можно последовательно
выявить, продолжая просмотр треугольников после завершения отслеживания
границы. После этого необходимо определить, какая из границ является
внешней, а какие границы -- внутренними. Это можно сделать, сравнив
между собой координаты (например, по ![]() ) крайних точек для всех границ.
(Максимальная кооордината будет у внешней границы.)
) крайних точек для всех границ.
(Максимальная кооордината будет у внешней границы.)
Заметим, что некоторая внутреняя граница одной закрашенной области является
внешней границей для другой области. Более того, области могут образовывать
иерархию, которую можно представить в виде дерева принадлежности областей.
Для этого можно считать, что корень дерева соответствует всей векторизуемой
области, а следующий уровень дерева соответствует закрашенным областям
первого уровня. Внутри области первого уровня может находиться несколько
областей второго уровня и т.д. Тогда полигоны множества ![]() необходимо
сформировать в виде элементов дерева принадлежности. Это можно сделать в
процессе классификации треугольников, если начать с какого-либо треугольника,
лежащего на границе всей векторизуемой области.
необходимо
сформировать в виде элементов дерева принадлежности. Это можно сделать в
процессе классификации треугольников, если начать с какого-либо треугольника,
лежащего на границе всей векторизуемой области.
1. Интерполяция линейных объектов, состоящая в автоматическом построении промежуточных точек, когда заданы начальная и конечная точки. При наличии графовой модели задача формулируется как нахождение кратчайшего пути по графу между двумя вершинами.
2. Экстраполяция контурных объектов - построение контура площадного объекта вблизи точки, указанной пользователем.
С использованием триангуляции задача может быть сформулирована как выбор подмножества треугольников триангуляции около заданной точки, удовлетворяющих заданному критерию.
Для решения этих задач можно использовать алгоритм Дейкстры [1].
Алгоритм ищет путь от начальной до любой другой вершины на графе за
время ![]() . Для планарного графа, у которого число ребер не превышает
. Для планарного графа, у которого число ребер не превышает
![]() , это слишком много. Для ускорения алгоритма можно организовать
текущее множество вершин, рассматриваемое на очередном шаге
алгоритма, в виде пирамиды (двоичного дерева) с минимальным
расстоянием в корне пирамиды. Между списками вершин и элементами
пирамиды делжны быть взаимные ссылки. Любое действие с вершиной
графа в пирамиде (вставка, удаление, просеивание при изменении
расстояния) выполняется за время
, это слишком много. Для ускорения алгоритма можно организовать
текущее множество вершин, рассматриваемое на очередном шаге
алгоритма, в виде пирамиды (двоичного дерева) с минимальным
расстоянием в корне пирамиды. Между списками вершин и элементами
пирамиды делжны быть взаимные ссылки. Любое действие с вершиной
графа в пирамиде (вставка, удаление, просеивание при изменении
расстояния) выполняется за время ![]() . Количество действий
равно числу ребер в графе. Тогда время выполнения всего алгоритма
Дейкстры для планарного графа составит
. Количество действий
равно числу ребер в графе. Тогда время выполнения всего алгоритма
Дейкстры для планарного графа составит ![]() .
.
На самом деле алгоритм Дейкстры может просмотреть лишь некоторую
часть из ![]() вершин графа, пока не доберется до конечной вершины.
Но даже в этом случае он делает много лишней работы, так как
просматривает вершины по всем направлениям, не учитывая, в каком
направлении от начальной находится конечная вершина.
вершин графа, пока не доберется до конечной вершины.
Но даже в этом случае он делает много лишней работы, так как
просматривает вершины по всем направлениям, не учитывая, в каком
направлении от начальной находится конечная вершина.
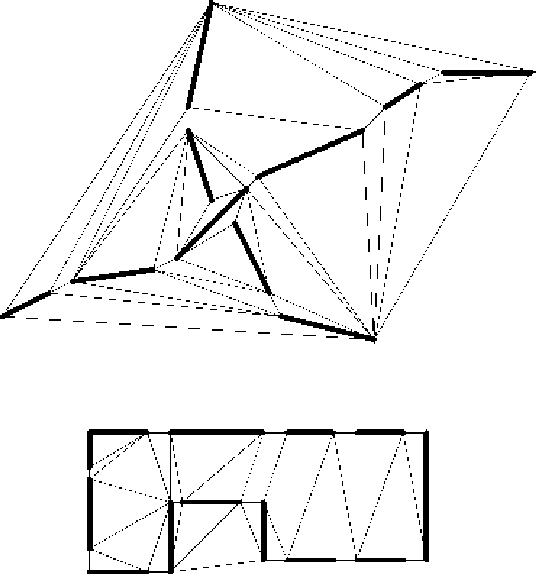
Пусть ![]() -- вершина на кратчайшем пути из вершины
-- вершина на кратчайшем пути из вершины ![]() в
конечную, соединенная с
в
конечную, соединенная с ![]() ребром, как это показано на рис. 3.
ребром, как это показано на рис. 3.
Утверждение. Оценочная функция ![]() подчиняется
монотонному ограничению, т.е. одновременно выполняются условия:
подчиняется
монотонному ограничению, т.е. одновременно выполняются условия:
1)
![]() , где
, где ![]() -- оптимальное расстояние из
начальной вершины в
-- оптимальное расстояние из
начальной вершины в ![]() ,
,
2)
![]() , где
, где ![]() -- оптимальное расстояние из
вершины
-- оптимальное расстояние из
вершины ![]() в конечную вершину,
в конечную вершину,
3)
![]() , где
, где ![]() -- оценка стоимости ребра
-- оценка стоимости ребра
![]() .
.
Доказательство. Следует из справедливости неравенства треугольника для евклидова расстояния.
Алгоритм информированного поиска с монотонным ограничением
называют алгоритмом ![]() . Он всегда находит кратчайшее
расстояние. В наихудшем случае его трудоемкость такая же, как у
алгоритма Дейкстры, однако на практике он обычно работает в
несколько раз быстрее. Тем не менее при большом расстоянии между
начальной и конечной вершинами и сильно заполненном графе время
может оказаться чрезмерным.
. Он всегда находит кратчайшее
расстояние. В наихудшем случае его трудоемкость такая же, как у
алгоритма Дейкстры, однако на практике он обычно работает в
несколько раз быстрее. Тем не менее при большом расстоянии между
начальной и конечной вершинами и сильно заполненном графе время
может оказаться чрезмерным.
Рассмотрим еще один алгоритм -- алгоритм градиентного поиска в
глубину. От обычного алгоритма поиска в глубину на графе (начиная
от начальной точки) он отличается тем, что ребра очередной вершины
просматриваются по возрастанию углов между ребром и направлением
на конечную вершину. При этом задается максимальное значение угла,
поэтому часть ребер заведомо исключается из просмотра. Кроме того,
так как при первом движении вглубь какой-либо вариант маршрута
будет найден, то при последующих просмотрах от очередной вершины
![]() мы будем иметь не только оценку пути снизу по формуле
(1), но и оценку сверху, поэтому более длинный путь можно
сразу же исключить. На рис. 2 при первом движении алгоритм найдет
вариант пути (1), затем при обратном ходе в процессе поиска --
вариант пути (2), и только потом -- кратчайший путь (жирная
линия).
мы будем иметь не только оценку пути снизу по формуле
(1), но и оценку сверху, поэтому более длинный путь можно
сразу же исключить. На рис. 2 при первом движении алгоритм найдет
вариант пути (1), затем при обратном ходе в процессе поиска --
вариант пути (2), и только потом -- кратчайший путь (жирная
линия).
Алгоритм градиентного поиска в глубину не гарантирует нахождение
минимального пути, однако во многих практических случаев он его
находит либо дает вполне удовлетворительное решение. Его время
работы обычно в несколько раз меньше, чем время работы алгоритма
![]() .
.
Рассмотрим несколько аспектов применения рассмотренных алгоритмов при практической объектной векторизации.
1. Пользователь может указать произвольную точку (в качестве начальной или конечной), которая может не совпасть с вершиной графа или даже не попасть на ребро. По предварительно построенной триангуляции можно быстро определить треугольник, куда попала точка, а в нем (или в одном из соседних треугольников) -- ближайшее ребро -- отрезок. Для поиска следует использовать ближайшую точку на отрезке, временно вставив в граф новую вершину.
2. При наличии помех -- разрывов линий на исходном растре -- можно допустить прохождение пути по "виртуальным'' ребрам, имеющим длину не больше заданной. В качестве таких "виртуальных'' ребер могут выступать, во-первых, невидимые ребра триангуляции. Кроме того, по триангуляции вокруг любой вершины легко организовать просмотр ближайших вершин, оценивая до них расстояние.
3. Иногда требуется, чтобы путь проходил только по ребрам с определенными параметрами, например, имеющим некоторую конкретную толщину или цвет. Дополнительное отсечение ребер также легко задать в рассмотренных алгоритмах.
4. Наконец, пользователь всегда может проконтролировать результат, и если по каким-то причинам найденный путь его не устраивает, то в алгоритме можно легко предусмотреть возможность задания промежуточных точек на еще не найденном варианте пути. В этом случае алгоритм должен выполняться в несколько последовательных этапов.
Вначале рассмотрим алгоритм, использующий вспомогательные точки. Он основан на алгоритме Дейкстры, но имеет следующую особенность: в нем начальной и конечной вершинами пути на графе служит одна и та вершина. Другие вспомогательные вершины (если они есть) разбивают путь на несколько последовательных участков, что помогает найти правильное (с точки зрения пользователя) решение в сложных случаях.
Вспомогательные точки служат еще одной цели: они позволяют ограничить геометрический размер области поиска. Если пользователь ставит вспомогательную точку в наиболее удаленном месте контура от базовой точки, то тем самым определяется круг, внутри которого должен располагаться весь контур.
Чтобы получить контур с обходом по часовой стрелке, путь от наиболее удаленной вспомогательной вершины надо начинать по ребру, направленному вправо от вектора, соединяющего базовую точку с этой вспомогательной вершиной. При дальнейшей работе алгоритма веса ребер умножаются на коэффициент тем больший единицы, чем больше движение отличается от кругового вокруг базовой точки. Для отрицательного направления этот коэффициент должен быть настолько большим, чтобы такой обход получался лишь при невозможности более длинных обходов с положительным направлением.
Если вспомогательных вершин несколько, то они могут использоваться для контроля того, что контур проходит через все эти вершины. В противном случае можно произвести обход из второй вершины, а затем объединить полученные обходы в один.
И, наконец, еще один контроль состоит в проверке того, что базовая вершина попала внутрь контура. Это осуществляется простым алгоритмом, изложенным, например, в [5].
Рассмотренный алгоритм может справиться даже с такой ситуацией, когда искомый контур разделен на части, как показано на рис. 3. Правда, тогда пользователю потребуется поставить больше вспомогательных точек, чем в простых случаях.
Алгоритм, не использующий вспомогательные точки, основан на поиске в глубину. Вначале по триангуляции ищется треугольник, внутрь которого попала базовая точка, и обход начинается с одной из вершин этого треугольника (соответствующей вершине в графе линий). Алгоритм начинает поиск в глубину, упорядочивая ребра начальной точки по углу против часовой стрелки от вектора, соединяющего начальную точку с базовой точкой. Для последующих точек угол отсчитывается относительно предшествующего в построенном пути ребра.Если контур построен, то проверяется, попала ли внутрь него базовая точка. Если не попала, то поиск в глубину продолжается, будет построен больший контур и т.д.
Если контур так и не удалось построить, то от начального треугольника, в который попала базовая точка, делается переход к соседнему (по смежной стороне), берется более удаленная точка от базовой и т.д.
В результате будет найден (если таковой существует) минимальный контур, объемлющий базовую точку.
Еще один алгоритм, не использующий вспомогательные точки, основан на разметке треугольников. В нем также вначале по триангуляции ищется треугольник, внутрь которого попала базовая точка. Этот треугольник помечается, как внутренний, после чего просматриваются ребра треугольника. Если ребро является линией на изображении, то оно пропускается, а если ребро невидимое, то делается переход к соседнему треугольнику, который тоже помечается как внутренний и т.д. Этот алгоритм разметки похож на алгоритм закраски пикселей растра с затравкой. Разметка треугольников заканчивается, когда весь минимальный контур будет заполнен размеченными треугольниками.
После этого необходимо отследить границу из ребер, отделяющих размеченные треугольники от неразмеченных.
Нетрудно видеть, что трудоемкость этого алгоритма -- ![]() , где
, где
![]() -- число треугольников внутри контура.
-- число треугольников внутри контура.
Для алгоритмов экстраполяции также рассмотрим несколько аспектов их применения на практике.
1. При наличии помех -- разрывов линий на исходном растре -- для этих алгоритмов также можно допустить прохождение контура по "виртуальным'' ребрам, имеющим длину не больше заданной, используя триангуляцию, как это показано на рис. 4.
2. Если требуется, чтобы контур проходил только по ребрам с определенными параметрами, например, определенной толщины или цвета, то в алгоритмах необходимо предусмотреть дополнительное отсечение ребер.
3. Как правило, размеры контуров относительно невелики. В то же время не исключена ситуация, когда из-за ошибок в изображении алгоритм не сможет найти малый корректный контур и будет тратить много времени на обнаружение заведомо неправильного большого контура. Для исключения таких ситуаций можно предусмотреть задание предельного размера контура.
 Ваши комментарии
Ваши комментарии
|
![[SBRAS]](/gif/s_sigma.gif)
[Головная страница] [Конференции] [СО РАН] |
© 2001, Сибирское отделение Российской академии наук, Новосибирск
© 2001, Объединенный институт информатики СО РАН, Новосибирск
© 2001, Институт вычислительных технологий СО РАН, Новосибирск
© 2001, Институт систем информатики СО РАН, Новосибирск
© 2001, Институт математики СО РАН, Новосибирск
© 2001, Институт цитологии и генетики СО РАН, Новосибирск
© 2001, Институт вычислительной математики и математической геофизики СО РАН, Новосибирск
© 2001, Новосибирский государственный университет
Дата последней модификации Wednesday, 12-Sep-2001 09:54:18 NOVST