 |

Куликов А.И.
Институт вычислительных технологий СО РАН
В настоящее время существуют различные алгоритмы сжатия изображений с потерей качества. Это означает, что процесс сжатия изображения происходит за счет потери части информации, которая считается наименее важной и больший коэффициент сжатия достигается за счет потери большего количества информации...Таким образом, фактически все имеющиеся алгоритмы такие как JPEG, рекурсивное сжатие и фрактальное сжатие, при больших коэффициентах сжатия дают свои не всегда хорошие эффекты (искажения, артефакты). Целью настоящей работы являлась разработка совершенно иного алгоритма сжатия с потерями качества. Он базируется на свойствах сетей Цао Ена. На данный момент, разработан и исследован алгоритм сжатия полно цветных изображений, достигнутый коэффициент сжатия составляет от 1:2 до 1:25, в зависимости от качества восстанавливаемого изображения.
В работе приведено краткое описание нейронных сетей Цао Ена, описан алгоритм сжатия и восстановления изображения с использованием этих сетей, приведено сравнение с известными алгоритмами сжатия и рассмотрены возможности алгоритма на разных классах изображений.
1. Сеть Цао Ена
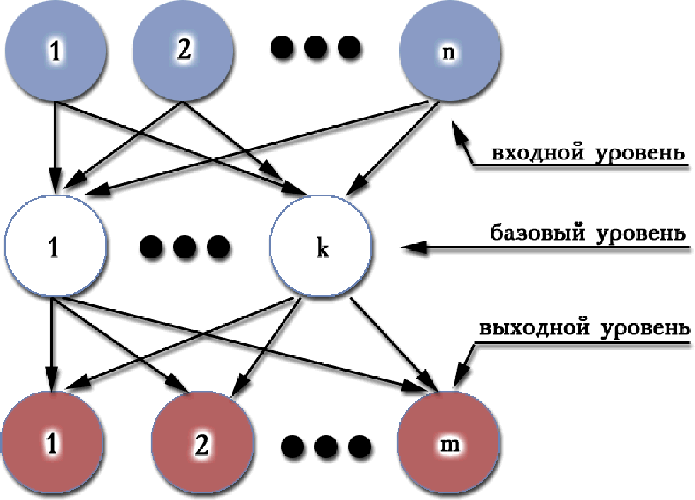
Сети Цао Ена разрабатывались для построения гладких замкнутых поверхностей в n-мерном пространстве по каркасу ключевых точек [1]. Поверхность Цао Ена в своей простейшей форме - это отображение гиперсферы на произвольную замкнутую поверхность в n-мерном пространстве. Для описания операций деформации (вытягивания) вводятся набор базовых точек находящихся одновременно на этой поверхности и на гиперсфере. Сама сеть, для преобразования n-мерной сферы по k базовым точкам в m-мерное пространство, представляет из себя трехуровневую нейронную сеть с n-входами, m-выходами и k-нейронами на базовом(среднем) уровне(слое) [2,4,3].
Схематически ее можно представить рисунком 1. Входной уровень составляют
передающие нейроны, со всеми
весовыми
коэффициентами равными 1 и без функции сопряжения. Поэтому они могут быть
заменены разветвителями. Каждый
нейрон
базового уровня фактически сопоставляет точку гиперсферы точке m-мерного
пространства. Целью функции
сопряжения у
нейронов базового уровня является усиление скорости падения выходного сигнала в
зависимости от
удаленности точки. Как
правило, в качестве функции сопряжения берут:
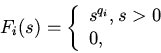
2. Применение сети Цао Ена для сжатия растровых 24-битных полноцветных изображений
При помощи сети Цао Ена можно делать сжатие растровых изображений с потерей качества за счет выбора базовых точек, по которым восстанавливается изображение с помощью обученной нейронной сети. Для сжатия строиться сеть преобразующая координаты изображения в цвет(RGB).
Для использования сети Цао Ена, координаты изображения преобразуются в координаты на гиперсфере. Возможны различные способы преобразования плоских координат в координаты на гиперсфере, например, в зависимости от размерности гиперсферы. Наиболее оптимально, преобразование на 4-ех мерную гиперсферу. Это преобразование записывается так:
(3)
![]() изображения
изображения
(4)
![]() изображения
изображения
(5)
![]() ,
,
![]() ,
,
![]() ,
,
![]() где
где
![]() точка на гиперсфере.
точка на гиперсфере.
Менее удачным будет использование гиперсферы с меньшей или большей размерностью, поскольку первая будет иметь несколько пиков на входе в адаптивный сумматор нейрона базового уровня, а вторая будет иметь избыточную информацию, приводящую к замедлению работы алгоритма.
Добавление каждой точки на базовый уровень делается по следующему правилу: координаты на гиперсфере заносятся как весовые значения для нейрона базового уровня, а значения цвета для нейронов выходного уровня.
В данной работе, были исследованы два альтернативных варианта нейронов на последнем слое нейронной сети.
Назовем максимизирующим нейроном, нейрон, выбирающий максимум из всех входных сигналов, затем умножающий его на вес связи, по которой был выбран максимум и не имеющий функции сопряжения. Назовем нейроном среднего взвешенного, нейрон, вычисляющий среднее взвешенное скалярного произведения входного сигнала на веса связей, по которым пришел сигнал.
Везде далее, будем рассматривать нейронную сеть с максимизирующим нейроном на последнем слое сети, поскольку работа с средним взвешенным аналогична. Таким образом, если точка (x,y,g,h) содержится в базовых точках сети, тогда при работе сети, на одном из нейронов базового уровня возникнет сигнал равный 1, и он будет выбран максимизируещей функцией нейронов выходного уровня, в результате на выходе получится требуемый цвет. Если точка не содержится в базовых точках, то максимальный сигнал возникнет на точке наиболее близкой к (x,y,g,h) и на выходе получим цвет в зависимости от нейрона и сигнала.
3. Алгоритм CNN. Сжатие изображения
Весь алгоритм сжатия можно представить схемой :
``Построение сети'' - это подготовка данных для обучения, преобразуются и заносятся все точки изображения в качестве базовых точек. Алгоритмами ``Обучение Сети'' исключаются все точки, без которых можно восстановить изображение с заданной точностью. ``Преобразование сети...'' преобразует сеть в более экономичный формат и ``Сжатие'' дополнительно сжимает данные без потерь.
Основными параметрами алгоритма являются: -качество (или допуск при обучении); -число рабочих строк; -точек в рабочей окрестности; -чувствительность по x; -чувствительность по y .
Допуск - задает порог допуска для обучения, такой что изображение будет восстановлено в рамках указанного допуска. Допуск задается в интервале от 0 до 255.
Число рабочих строк и ![]() в рабочей
окрестности определяет рабочую область для нейронной сети, это значит, что
сеть строится и функционирует только для этой области. Более подробно об
конкретном использовании рабочих областей описано в алгоритмах обучения.
Чувствительность по x и по y определяет крутизну
сигнала от базовой точки.
в рабочей
окрестности определяет рабочую область для нейронной сети, это значит, что
сеть строится и функционирует только для этой области. Более подробно об
конкретном использовании рабочих областей описано в алгоритмах обучения.
Чувствительность по x и по y определяет крутизну
сигнала от базовой точки.
4. Алгоритмы обучения
4.1. Простой предсказывающий алгоритм
Точки сети проверяются последовательно слева на право сверху вниз. По ходу проверки в буфер строк загружаются последние n используемых строк, а рабочая область служит локальной сетью Цао Ена для изображения. По сути, статическая рабочая область имеет постоянные размеры. Одним из достоинств алгоритма является возможность обрабатывать данные потоком - это значит, что данные могут поступать непрерывным потоком и достаточно быстро обрабатываться. Алгоритм основывается на возможности сети предсказать цвет следующей точки в потоке при известных предыдущих. Таким образом, для каждой точки проверяется можно ли ее восстановить на основании уже имеющихся точек в рабочей области. Если не удается восстановить точку с заданным допуском, она заносится в рабочую область или в глобальную сеть для всего изображения. Как видно проверка делается для каждой точки только один раз.
Все тесты реализации алгоритма проводились на компьютере с процессором Intel Pentium II - 350, где сжатие/восстановление изображения 540x370, c качеством 10, старым методом, проходило 9 минут 40 секунд / 6 минут, а новым, с статической рабочей областью 5x2, 6 секунд / 2 секунды. При этом коэффициент сжатия, который определяется в нашем случае как кол-во оставшейся информации в % , составил 28% и 31%.
4.2. Динамический интерполирующий алгоритм
Отличием динамического алгоритма является замена статических рабочих областей на динамические. Главным условием построения динамической области является обязательное наличие точек на правой и левой границах рабочей строки и отсутствие точек между граничными. Причем количество рабочих строк в данной реализации алгоритма остается постоянным, хотя теоретически и оно может быть динамическим.
Алгоритм основывается на возможности сети интерполировать значения между базовыми точками, и поэтому, как уже стало ясно, функция восстановления точки в этом алгоритме используется такая же как в предыдущем алгоритме - интерполирующая.
Сам алгоритм работает несколько медленнее всех предыдущих за счет увеличения числа проверок правильности восстановления, так как теперь при удалении каждой рабочей точки проверяются все отсутствующие точки в рабочей строке. Предыдущие строки не проверяются, поскольку влияния на них последующие при восстановлении не оказывают.
Рабочая точка находиться не в крайней левой позиции, как в предыдущих алгоритмах, а на точку левее от этой позиции. Это обусловлено появлением граничных точек.
Из условий накладываемых на рабочую область, получается, что с каждым удалением рабочей точки мы расширяем рабочую область, в противном случае рабочая область схлопывается.
Под схлопыванием рабочей области, будем понимать удаление всех точек слева на право до получения области размером 3 на n. При обучении область никогда не может быть меньше чем 3 на n, т.к. между двумя граничными точками должна быть рабочая точка. Поэтому одной из особенностей результата работы алгоритма является обязательное присутствие правой и левой границ изображения, что учитывается при преобразовании изображения в формат для хранения.
Сжатие/восстановление изображения 540x370, c качеством 10, проходило 22 секунд / 2 секунды. Коэффициент сжатия составил 36% .
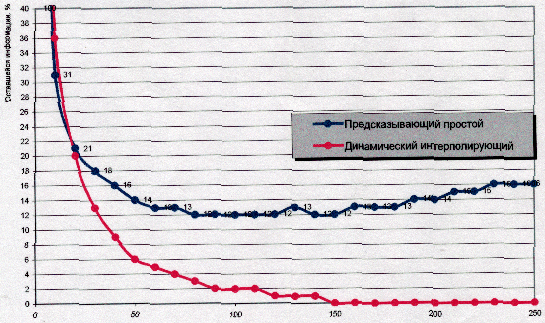
На рис. 3 изображен график, сравнивающий два алгоритма обучения:
Как видно из графика, при больших допусках динамический алгоритм дает лучшие результаты сжатия, конечно при этом он проявляет свои эффекты, при больших коэффициентах сжатия.
5. Алгоритмы преобразования сети для хранения
До этого раздела была рассмотрена первая и основная часть сжатия изображения, но преобразования в формат для хранения и последующее сжатие его(о чем речь пойдет в следующей главе) не менее важные вопросы, поскольку без решения этих проблем применение алгоритма не имело бы никакого смысла. Данные сети представляют собой пятерку чисел (x,y,R,G,B), причем x,y - Integer, а R,G,B - byte. То есть, для хранения нужно 2*2+3 = 7 байт на каждую точку, что даже при 10% сжатии даст только 23% реального сжатия. Это конечно возможный выход, но не самый удовлетворительный, потому было предложено использовать несколько форматов хранения данных, следующие два формата оказались наиболее хорошими и на настоящий момент реализованы:
5.1. Тегированный формат
Идея состоит в представлении непрерывных участков данных некоторыми кусочками - тегами. Каждый тег содержится в линии. Тег содержит следующую информацию - (x, count, bits) , где x, count - однобайтовые числа, а bits - это тройка (R,G,B). Как видно из определений x и count не могут принимать значений больших 255. Поэтому, когда возникает кусок непрерывных данных длинной более 255 точек он кодируется двумя тегами. А в большие изображения для представления данных в области x строго больше 255 разбиваются на фреймы или полоски. Каждая тег-линия содержит только информацию о количестве тегов в линии, ее номер вычисляется автоматически по возрастанию.
Таким образом, весь формат представляется иерархией: Фрейм - тег-линия - тег - точки.
5.2. RCE (Run count encoding)
Этот алгоритм несколько похож на известный всем алгоритм RLE, но с тем отличием, что RLE сжимает повторяющиеся последовательности, а RCE исключает из данных пустоты, то есть данные на выходе RCE-преобразования выглядят как совокупность точек и кол-ва пропусков. Алгоритм одномерный, поэтому перед его использованием или во время его использования данные преобразуются в одномерный поток.
6. Алгоритм CNN. Восстановление изображений
Алгоритм восстановления является обратным к алгоритму сжатия, поэтом все этапы проводятся в обратном порядке. Схематически весь алгоритм можно представить так:
Алгоритмы преобразования формата данных в сеть были уже описаны выше как обратные преобразования RCE и теггированного формата. Для работы алгоритмов восстановления требуются следующие параметры: число рабочих строк число точек в рабочей окрестности (для предсказывающий алгоритмов) чувствительность по X и по Y примечание: все эти параметры более подробно были описаны выше.6.1. Простой предсказывающий алгоритм восстановления
В этом алгоритме применяется статическая рабочая область. Статическая область строится так же, как и в одноименных алгоритмах обучения, поэтому для восстановления изображения нужно пройти по всем точкам получаемого изображения и восстановить их с соответствующей рабочей областью. Это займет h*w итераций. Поскольку при восстановлении точки, если она отсутствует в сети, мы будем использовать рабочую область n*m исключая эту точку, причем все предыдущие точки восстановлены, а это именно так как мы проверяли допуск в алгоритме обучения, то это гарантирует, что восстановленное изображение будет таким каким предполагалось алгоритмом обучения.
6.2. Динамический интерполирующий алгоритм восстановления
Как и в одноименном алгоритме обучения, так и тут применена динамическая рабочая область и интерполирующая функция восстановления точки. При восстановлении изображения мы обходим все точки изображения, так что бы динамическая область в рабочей строке содержала только текущую точку и границы, если точка отсутствует в сети. Если же точка есть в сети, то она восстанавливается как есть, то есть просто копируется в изображение. Понятно, что и этот алгоритм совершит h*w итераций. Время восстановления в среднем для обоих алгоритмов состовляет 0.1 от времени сжатия.
7. Другие возможности применения алгоритма CNN
Помимо своего основного предназначения - сжатия растровых изображений, алгоритм CNN можно применять и для восстановления переданных с искажениями изображений. Такая возможность может позволить использовать этот алгоритм для односторонней передачи изображений - это значит, что данные не будут пересылаться отправителем повторно, а получатель вовсе не будет посылать никаких сообщений, он будет только принимать. Это позволит использовать для передачи изображений односторонний канал и увеличить скорость передачи за счет отсутствия дополнительных пересылок. Правда надо заметить, что подобный алгоритм может применяться только там, где не нужна 100% достоверность изображения. Таким примером могут быть FAX-сообщения или подобные. Причем надо заметить, что даже при очень большой зашумленности канала, так что из информации удастся получить только 30% , восстановление будет вполне распознаваемо глазом. Для реализации такой возможности нужно будет только учесть, что протокол передачи изображений должен будет выявлять неверно переданные точки. Это можно сделать например по контрольной сумме. Надо заметить, что для восстановления будет применяться алгоритм схожий с алгоритмом восстановления изображения по сети и потому имеющий схожие временные характеристики. Потому можно сказать, что восстановление будет проходить достаточно быстро.
8. Сравнение с известными алгоритмами
Сжатие проводилось с параметрами:
качество: 30
число рабочих строк в сети: 2
число рабочих точек в окрестности: 5
чувствительность по x : 1000
чувствительность по y : 1000
Результаты приведены в таблице на стр.
| Изображение | CNN | JPEG | PNG | GIF(256c) | BMP |
| облако
[1536x1024] |
377Kb
206Kb* |
186Kb | 998Kb | 652Kb | 4609Kb |
| черно-белое (полноцветное фото, портрет)
[624x479] |
72Kb
38Kb* |
62Kb | 263Kb | 171Kb | 876Kb |
| цветное фото (портрет)
[254x384] |
61Kb
42Kb* |
32Kb | 172Kb | 81Kb | 287Kb |
| Текстура
[385x527] |
247Kb
171Kb* |
247Kb | 479Kb | 187Kb | 595Kb |
| изображение с высокой частотой на черном фоне
[407x480] |
149Kb
155Kb* |
43Kb | 238Kb | 78Kb | 574Kb |
| фотография здания
[617x696] |
316Kb
224Kb* |
64Kb | 862Kb | 304Kb | 1259Kb |
| деловая графика
[818x845] |
321Kb
208Kb* |
84Kb | 375Kb | 98Kb | 2027Kb |
| светлое изображение
[280x185] |
17Kb
12Kb* |
12Kb | 44Kb | 25Kb | 152Kb |
| изображение на
белом фоне [278x183] |
15Kb
9Kb* |
12Kb | 40Kb | 26Kb | 150Kb |
9. Реализация
Данный алгоритм был реализован для компьютеров серии Pentium, под
операционную систему Windows 95, 98, NT/2000, на языке программирования
Visual C++ 6.0. Вычислительное ядро написано на ANSI C, что позволяет его
переносить под UNIX. Для тестирования и исследования алгоритма был создана
программа, имеющая удобный графический интерфейс.
В программу вошли: 3 алгоритма обучения, 3 алгоритма усиления сжатия и
дополнительное сжатие при помощи алгоритма Хаффмана.
Программа позволяет:
считывать изображения в формате BMP и CNN;
производить сжатие и распаковку;
просматривать и сравнивать результаты визуально;
сохранять базовые точки для изображения;
настраивать параметры обучения;
загружать в сеть испорченные изображения и восстанавливать их;
портить изображения псевдослучайным шумом.
Заключение
Представляются перспективными: -проверка возможности перехода с RGB на HUE; -проверка использования алгоритма Хаффмана для каждой цветовой плоскости по отдельности, используя особенности статических областей; -увеличение сжатия за счет хранения только разности статических областей; -разработка алгоритмов для сжатия видео; -разработка алгоритмов для сжатия трехмерных сцен и срезов; -разработка алгоритмов для гладкого масштабирования при помощи сети Цао Ена; -учтя результаты работы со статической областью, можно построить более эффективный, чем RCE, алгоритм, основанный на повторяемости статических областей, в местах с малой частотой. Предполагается, что это позволит увеличить качество от 1.5 до 3-х раз; -тестирование возможностей распараллеливания вычисления при сжатии; -перенос под UNIX .
 Ваши комментарии
Ваши комментарии
|
![[SBRAS]](/gif/s_sigma.gif)
[Головная страница] [Конференции] [СО РАН] |
© 2001, Сибирское отделение Российской академии наук, Новосибирск
© 2001, Объединенный институт информатики СО РАН, Новосибирск
© 2001, Институт вычислительных технологий СО РАН, Новосибирск
© 2001, Институт систем информатики СО РАН, Новосибирск
© 2001, Институт математики СО РАН, Новосибирск
© 2001, Институт цитологии и генетики СО РАН, Новосибирск
© 2001, Институт вычислительной математики и математической геофизики СО РАН, Новосибирск
© 2001, Новосибирский государственный университет
Дата последней модификации Monday, 01-Oct-2001 22:19:09 NOVST