Половикова О.Н. Применение кластерного анализа для математического моделирования информационно-поисковых систем
(АГУ, г. Барнаул, Россия)
Поиск (информационный поиск)- одна из ключевых операций информационно-поисковых систем (ИПС). ИПС согласно правилам перевода с естественного языка на информационно-поисковый преобразует потребности потребителя для выполнения поиска, затем система осуществляет обратный перевод результатов поиска на естественный язык.
В процессе разработки ИПС возникают задачи поиска не конкретного ресурса, а совокупности ресурсов из определенной области знаний. Для решений этой задачи необходимо определить технологию (метод) оптимального разбиения (классификации) ресурсов на блоки, представить множество ресурсов некоторым числом групп (таксонов). Количество таксонов должно принадлежать некоторому заданному отрезку (указаны возможные пределы).
При этом следует показать, что ресурсы, соответствующие одному таксону, были бы достаточно близки друг к другу с точки зрения некоторого критерия близости, а ресурсы из разных таксонов были бы достаточно далеки друг от друга по этому критерию.
Определим (сформулируем) задачу разбиения множестваинформационный ресурсов (ИР) на тематические разделы как задачу кластерного анализа.
Пусть задано множество состояний БД 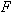 . Каждое состояние предполагает, что выбрана система данных
. Каждое состояние предполагает, что выбрана система данных 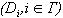 , и для каждого
, и для каждого 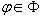 указана реализация этого символа отношений в системе
указана реализация этого символа отношений в системе 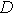 , где - это декартовое произведение всех доменов (сортов) множеств данных
, где - это декартовое произведение всех доменов (сортов) множеств данных 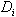 ,
, 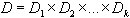 ,
, 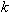 - мощность множества
- мощность множества 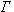 . Каждый информационный ресурс схеме
. Каждый информационный ресурс схеме 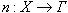 определяется набором параметров
определяется набором параметров 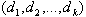 , где
, где 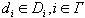 .
.
Пусть 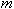 - целое число, меньшее, чем
- целое число, меньшее, чем 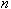 . Задача кластерного анализа заключается в том, чтобы на основании данных разбить множество информационных ресурсов на кластеров (подмножеств) -
. Задача кластерного анализа заключается в том, чтобы на основании данных разбить множество информационных ресурсов на кластеров (подмножеств) - 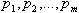 так, чтобы каждый ИР
так, чтобы каждый ИР 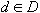 принадлежал только одному кластеру и чтобы ИР, принадлежащие одному и тому же кластеру, были сходными, в то время как ИР, принадлежащие разным кластерам, были разнородными (несходными). Для каждой пары ИР необходимо определить их близость (степень близости). По значению близости (степени близости) следует либо поместить ресурсы в один кластер либо в разные кластеры.
принадлежал только одному кластеру и чтобы ИР, принадлежащие одному и тому же кластеру, были сходными, в то время как ИР, принадлежащие разным кластерам, были разнородными (несходными). Для каждой пары ИР необходимо определить их близость (степень близости). По значению близости (степени близости) следует либо поместить ресурсы в один кластер либо в разные кластеры.
Решением задачи кластерного анализа является такое разбиение ресурсов на кластеры , которое удовлетворяет некоторому математическому критерию качества кластеризации (критерию оптимальности). Этот критерий может быть записан в виде функционала, выражающий уровни желательности различных разбиений множества ИР на тематические разделы.
При разработке критерия качества кластеризации следует учитывать следующие неформальные требования :
- Внутри одного кластера объекты должны быть связаны между собой;
- Объекты из разных кластеров должны быть далеки друг от друга;
- При прочих равных условиях распределение объектов по кластерам должно быть равномерно.
Важным свойством для кластера являются связность (близость) - эти свойства предоставляют основу для построения функций критерия качества разбиения. Для количественного измерения сходства двух объектов необходимо построить функцию меры близости двух объектов. От данной функции зависит выбор варианта разбиения объектов на кластеры при заданном алгоритме разбиения.
Выбор признаков ресурсов - признаков сходства, по значениям которых можно судить о сходстве (близости) между ресурсами, зависит от определения понятия "тематический раздел". Тематический раздел - совокупность информационных ресурсов из определенной области знаний. Таким образом, в качестве признаков сходства можно использовать наборы ключевых слов.
Информацию о близости конкретного ресурса с другими можно получить только при попарном сравнении наборов ключевых слов двух ресурсов. При таком подходе каждой паре ресурсов можно поставить в соответствие число совпадений между значениями ключевых слов этих ресурсов, это значение будет являться значением мера близости на данной паре ресурсов. Полученная таким образом меры близости характеризует не конкретный ресурс, а пару ресурсов.
Для того чтобы добиться точности идентификации запроса или нового ресурса в совокупности тематических разделов, следует информационные разделы сформировать максимально "непохожими", а ресурсы одного раздела максимально "похожими". Поэтому характеристическая функция критерия качества разбиения должна зависеть от сходства ресурсов (объектов) внутри каждого кластера и от различия между кластерами (при попарном сравнении).
Пусть определена функция среднего сходства объектов по всем полученным кластерам (вычислили среднее сходство объектов для каждого кластера - 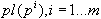 , затем вычислили среднее значение
, затем вычислили среднее значение 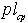 для множества значений
для множества значений 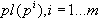 . Пусть также определена функция среднего различия для построенных кластеров:
. Пусть также определена функция среднего различия для построенных кластеров:
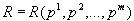 .
.
Тогда характеристическую функцию критерия качества разбиения определим как
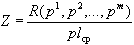 ,
которую необходимо максимизировать. Для этого следует как можно больше сделать значение числителя и как можно меньше значение знаменателя выражения.
,
которую необходимо максимизировать. Для этого следует как можно больше сделать значение числителя и как можно меньше значение знаменателя выражения.
Анализ существующих методов кластеризации позволил сделать вывод, что приемлемыми методами для решения поставленной задачи являются иерархические агломеративные методы. Исключение совокупности возможных методов классификации связано со спецификой решаемой задачи - это, прежде всего, отсутствие аппарата для построения матрицы числовых значений признаков близости ИР (матрицы данных).
Разработаны и используются различные алгоритмы для решения задач кластеризации:
- алгоритмы класса FOREL -FOREL, FOREL-2, SKAT, KOLAPS, BIGFOR;
- алгоритмы динамической кластеризации - DINA, SETTIP;
- алгоритм ROST;
- алгоритмы KRAB (КРАБ) и другие.
Алгоритмы семейства КРАБ, как и ручная кластеризация, учитывают не абсолютные расстояния, а отношения расстояний между несколькими соседними точками, что согласуется со спецификой выбранной меры близости для задачи разбиения множества ресурсы на тематические разделы.
Определим следующий граф: вершины графа - это точки, интерпретирующие информационные ресурсы, вершины графа попарно соединены и образуют ребра графа, длина ребра соответствует значению меры близости между соответствующими ресурсами. Обозначим через  длину ребра между двумя точками. Среди всех ребер, смежных данному ребру, найдем самое короткое и его длину обозначим через
длину ребра между двумя точками. Среди всех ребер, смежных данному ребру, найдем самое короткое и его длину обозначим через 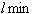 . Отношение будем называть -длиной ребра. Большие значения имеют ребра, которые соединяют удаленные друг от друга точки, окруженные близкими соседями. Именно такие точки находятся в центре внимания алгоритмов семейства КРАБ.
. Отношение будем называть -длиной ребра. Большие значения имеют ребра, которые соединяют удаленные друг от друга точки, окруженные близкими соседями. Именно такие точки находятся в центре внимания алгоритмов семейства КРАБ.
Алгоритм семейства КРАБ находит компактные сгустки точек, используя 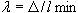 -расстояние (как и человек при ручной кластеризации). Другими словами, он базируется на гипотезе
-расстояние (как и человек при ручной кластеризации). Другими словами, он базируется на гипотезе 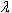 -компактности. Если при построении алгоритма будем использовать приемы алгоритма семейства КРАБ, то необходимо показать, что гипотезой -компактности можно воспользоваться для решения задачи классификации множества информационных ресурсов на разделы.
-компактности. Если при построении алгоритма будем использовать приемы алгоритма семейства КРАБ, то необходимо показать, что гипотезой -компактности можно воспользоваться для решения задачи классификации множества информационных ресурсов на разделы.
Формулировка гипотезы -компактности опирается на понятие -расстояния. Определим через множество точек, соответствующих информационным ресурсам пространства. Вычислим -расстояния для всех точек (ресурсов) из множества . Построим граф без петель, который соединяет между собой все точки ребрами, суммарная -длина которых минимальна -кратчайший незамкнутый путь (КНП). Теперь -расстоянием между двумя любыми точками (вершинами) будем считать сумму -длин тех ребер, по которым проходит путь между ними по КНП.
Гипотеза компактности (в частности и гипотеза -компактности) основывается на предположении, что заданные признаки объектов определяют свойство, по которому объекты легко разделяются. Это предположение легло в основу гипотезы компактности (и гипотезы -компактности): классам объектов (кластерам) соответствуют некоторые компактные множества в пространстве признаков. При этом объекты могут отражаться в этом пространстве не в зависимости от значения признака, а в зависимости от сравнения значений признака по разным объектам.
Предположение о разделимости объектов на кластеры, исходя из сопоставлений -расстояний между объектами, полностью вписываются в сделанные раннее построения по классификации информационных ресурсов. Рассмотрим выводы, подтверждающие это предположение. Признаками близости ресурсов (объектов) могут быть характеристики пользователя учебного заведения (факультет, курс, класс и т.д.) и ключевые слова ресурса. Сопоставление объектов происходит по совпадению соответствующих им значений признаков близости, например, по совпадению множеств из ключевых слов: чем больше совпадений по ключевым словам, тем объекты расположены ближе друг к другу в признаковом пространстве.
Те объекты (ресурсы), которые при попарном сопоставлении имеют относительно (сравнивая с другими объектами) большее число совпадений по значениям признаков (ключевым словам) образуют в пространстве признаков компактные сгустки. Определим кластер как совокупность объектов с большим (относительно сравнения с другими объектами) совпадением значений признаков при попарном сопоставлении. При таком определении кластер отображается в пространство признаков как сгусток точек.
При попарном сопоставлении объектов одного кластера с объектами других кластеров получаем меньше совпадений значений признаков (относительно сравнения с объектами этого же кластера). Поэтому можно утверждать, что в пространстве признаков кластера разнесены (отделены) относительно друг друга. Значения построенной функции близости пары ресурсов является исходными данными для определения -расстояния между объектами.
Для апробации предлагаемого алгоритма кластеризации (основанного на принципах алгоритма KRAB) использовалась выборка данных (1094 информационных ресурса) электронного каталога библиотеки Алтайского госуниверситета. Выборка данных включает следующие свойства ресурсов:
- название ресурса,
- набор ключевых слов и
- название тематической рубрики (использовалась только для проверки корректности работы алгоритма).
Использовалась целевая функция критерия качества кластеризации 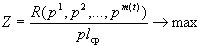 и следующие ограничения:
и следующие ограничения:
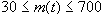 - неравенство, определяющее количество кластеров,
- неравенство, определяющее количество кластеров,
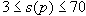 - неравенство, определяющее количество объектов в кластере.
- неравенство, определяющее количество объектов в кластере.
В результате выполнения предварительного шага кластеризации были построены 180 связанных подмножеств, мощность которых удовлетворяет ограничению на количество объектов в кластере и одно (1-ое) связанное подмножество (632 точки), мощность которого не удовлетворяет данному ограничению.
Для кластеризации 1-ого связанного подмножества использовался модифицированный алгоритма KRAB. Модификация связана с ограничениями на область определения целевой функции  и особенностями предметной среды:
и особенностями предметной среды:
- особенностью построения функции близости и матрицы напряженности;
- необходимостью определения связанных подмножеств - нулевой шаг кластеризации;
- возможностью за один шаг кластеризации разрывать несколько "напряженных" ребер.
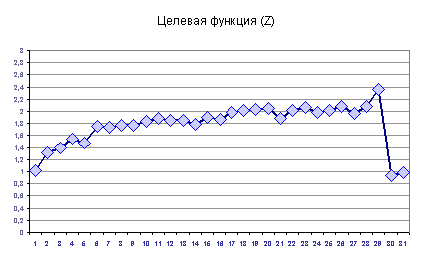
Для кластеризации 1-ого подмножества использовались основные шаги выбранного алгоритма. Было выполнено 32 шага кластеризации (см. рис. 1). Мощность одного из кластеров, полученных на 32-ом шаге кластеризации, равна 2, что противоречит ограничению на количество ресурсов в кластере, поэтому, согласно правилам используемого алгоритма, процесс кластеризации необходимо завершить и использовать результаты только с 1 по 31 шаг кластеризации.
Рассмотрим график целевой функции (см. рис. 1) Максимальное значение (2.367) достигается на 29 шаге кластеризации. Таким образом, оптимальное разбиение 1-ого связанного подмножества включает 41 кластер, минимальный кластер включает 3 точки (объекта), максимальный - 71 точку. Оптимальное разбиение 1-ого подмножества отвечает ситуации, когда внутреннее среднее сходство между ресурсами одного тематического раздела более чем в два раза превышает среднее сходство между ресурсами из различных тематических разделов.
Промежуточные данные, полученные при выполнении кластеризации 1-ого подмножества, а также нулевой шаг кластеризации отражены на динамической странице http://dbs.asu.ru/pon.knp.write_kl.
 Библиография
Библиография
- Дюран Б., Оделл П. Кластерный анализ. Пер. с анг. Е.З. Демиденко / Под ред. А.Я. Боярского. Предисловие А.Я. Боярского. - М.: Статистика, 1997.
- Загоруйко Н.Г. Прикладные методы анализа данных и знаний. - Новосибирск: Издательство Института математики, 1999.
- Загоруйко Н.Г., Елкина В.Н., Емельянов С.В., Лбов Г.С. Пакет прикладных программ ОТЕКС. - М.: Финансы и статистика, 1986.