
Рис.1 Структура беспалитрового BMP-файла
Предлагается метод определения наличия "скрытой" информации в графических
данных формата BMP. Экспериментально показано, что эффективность метода
выше, чем у ранее известных.
Бурное развитие вычислительной техники и наличие новых систем передачи информации приводит к широкому использованию стеганографических алгоритмов, т.е. таких методов передачи данных, когда сам факт передачи скрыт от постороннего наблюдателя. Обычно скрыто передаваемые сообщения встраивают в "невинные" данные - фотографии, спам, видео, аудиозаписи и т.п. Методы современной компьютерной стеганографии находят применение в области военной и правительственной связи, защиты авторских прав и других областях [1]. Очевидно, что методы стеганографии могут использовать и самые разнообразные "злоумышленники", поэтому становится актуальной задача т.н. стегоанализа, предназначенного для обнаружения "скрытой" информации.
Секретные данные встраиваются в файлы различных форматов, обычно называемые "контейнерами". Контейнер называется пустым, если он не содержит скрытой информации, в противном случае он называется стегоконтейнером или заполненным контейнером.
Целью данной работы является построение эффективного метода "автоматического" (т.е. без участия человека) определения факта наличия скрытых данных в графических файлах формата BMP. В настоящее время существуют многочисленные алгоритмы и программы, предназначенные для встраивания "скрытой" информации в файлы формата BMP. (см. например обзор в [1,3]). Задача стегоанализа данных в формате BMP также привлекает многих исследователей [4,5,6,7].
В данной работе предлагается новый метод стегоанализа, основанный на применении сжатия данных. Среди достоинств разработанного метода следует подчеркнуть высокую эффективность, скорость, применимость к широкому классу методов модификации LSB (least significant bits) пикселов изображения, а также то, что стегоанализ проводится без участия человека.
Остановимся на описании формата BMP. Он имеет много разновидностей, составляющих два класса - палитровые (индексированные) и беспалитровые. При этом сложность стегообработки палитровых форматов делает их применение редким. Наиболее используемыми в качестве контейнеров являются беспалитровые форматы. Следует отметить, что нельзя использовать один и тот же стеганографический алгоритм для включения данных методом замены младших значащих бит для обоих классов.
BMP-файл состоит из заголовка - структуры размером в несколько десятков байт, содержащей основные параметры изображения (размеры, глубину цвета и т.д.). Следующим элементом структуры является палитра - массив, описывающий цвета, используемые в изображении. Каждый элемент палитры состоит из 4-х байт (R-,G-,B-компоненты и альфа-канал). Размер палитры 1Кб. Палитра не является обязательной в некоторых типах BMP-файлов. Последняя часть - область данных - содержит последовательность кодов пикселов изображения.
В беспалитровых изображениях палитра, как правило, отсутствует, а область данных содержит описание всех цветовых компонент каждого пикселя изображения (см. Рис. 1).
Включение скрытых данных в этом случае производится без всяких дополнительных преобразований. Самым простым и поэтому наиболее распространенным форматом данного класса является 24-битный BMP. По этой причине в работе исследуются изображения только такого формата.
Рассматривается задача разработки метода определения факта наличия скрытых данных автоматически, без привлечения на отдельных этапах аналитических способностей человека. Это, в частности, позволит значительно ускорить процесс тестирования серий из большого числа изображений при реализации методода в качестве "фильтра" в системах централизованного управления интернет-трафиком (маршрутизаторы, прокси-серверы и т.д.) для организации автоматизированного поиска "скрытых" данных в пересылаемой информации.
Перейдем к описанию метода. Мы используем новый подход в стегоанализе, который базируется на сжатии данных. При этом в предлагаемом методе могут применяться широко распространенные программы-архиваторы.
Идея метода опирается на то, что включаемые данные статистически независимы от "контейнера", поэтому при сжатии объем полученного архивного файла возрастает по сравнению со сжатием исходного "пустого" контейнера.
Метод состоит в сравнении коэффициентов сжатия исследуемого контейнера и его копии, полностью заполненной случайной последовательностью данных. Если коэффициенты близки по значению, т.е. их разность достаточно мала, то весьма вероятно, что исходный файл содержал скрытую информацию. При практической реализации этой идеи контейнер и его заполненная копия рассматриваются не целиком, а делятся на несколько равных частей, после чего оцениваются коэффициенты сжатия соответствующих частей. Это позволяет увеличить точность метода.
Формально разработанный алгоритм выглядит следующим образом. Пусть X = {x1, ... ,xN } - последовательность байтов в поле данных изображения BMP, где |X| = N - длина последовательности.
Разобьем последовательность X на d равных отрезков и обозначим каждый отрезок Xi, где i = 1,2, ... ,d. Пусть Ψ(X) - алгоритм сжатия, примененный к последовательности X. Введем величину
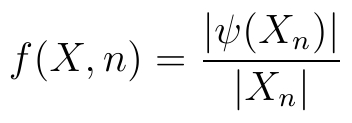
Обозначим через φ(X) псевдослучайное изменение младших бит всех байтов последовательности X. Пусть X - последовательность, которая подается на вход программе, а Y = φ(X) - полученная из нее новая последовательность ("заполненный" контейнер). Исходная последовательность X должна сжиматься "сильнее" по сравнению с измененной последовательностью Y, если исходный контейнер не заполнен или частично заполнен.
Введем новую величину

Если отрезок Xi последовательности X содержит "скрытую" информацию, то коэффициент f(X,i) и отвечающий ему f(Y,i) отличаются незначительно, и напротив, "пустой" участок сжимается лучше "заполненного". Для определения факта включения информации выбирается пороговое значение для величины δ и производится оценка количества отрезков, на которых значение величины не превышает порог. Если таких отрезков больше d/2, то считается, что исходная последовательность X содержала скрытые данные, в противном случае последовательность X считается "пустой". Порог можно варьировать, регулируя тем самым частоту ошибок программы на пустых и непустых контейнерах.
Для экспериментального исследования метода была подготовлена серия из 1000 случайно отобранных изображений ("контейнеров") формата 24-бит BMP. На вход программы подавались исходные контейнеры, контейнеры, заполненные на 10%, 20%, и т.д. от своей емкости. (Под емкостью контейнера понимается максимальный объем информации, который можно в него "спрятать". Емкость зависит от характеристик контейнера, таких как формат, размер файла и т.д. и от выбора алгоритма включения данных в этот контейнер.) Были проверены различные методы заполнения контейнеров, архиваторы и значения порогов δ.
Назовем для краткости ошибкой 1-го рода случай, когда метод принимает пустой контейнер за заполненный, и наоборот, назовем ошибкой 2-го рода случай, когда непустой контейнер принимается за пустой.
В качестве архиваторов использовались RAR, ZIP, GZIP, BZIP2. RAR показал минимальную по сравнению с другими ошибку 1-го рода (см. Табл. 1)
| Архиватор | Пороговое значение δ | ||||||||||||
| 0,8 | 0,9 | 1,0 | 1,1 | 1,2 | 1,3 | 1,4 | 1,5 | 1,6 | 1,7 | 1,8 | 1,9 | 2,0 | |
| RAR | 0% | 0% | 0% | 0% | 1% | 1% | 1% | 2% | 2% | 3% | 3% | 3% | 3% |
| ZIP | 0% | 1% | 1% | 1% | 1% | 1% | 2% | 2% | 2% | 4% | 4% | 4% | 5% |
| GZIP | 0% | 0% | 1% | 1% | 1% | 2% | 2% | 2% | 3% | 3% | 3% | 3% | 4% |
| BZIP2 | 0% | 0% | 1% | 1% | 2% | 2% | 3% | 3% | 5% | 6% | 6% | 7% | 7% |
Архиваторы ZIP и BZIP2 продемонстрировали минимальные ошибки второго рода (см. Табл. 2)
| Архиватор | Степень наполнения контейнера | ||||||||||
| 0% | 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% | |
| RAR | 0% | 3% | 6% | 21% | 89% | 99% | 98% | 98% | 98% | 98% | 98% |
| ZIP | 1% | 3% | 12% | 30% | 94% | 100% | 100% | 100% | 100% | 100% | 100% |
| GZIP | 1% | 3% | 12% | 28% | 93% | 100% | 100% | 100% | 100% | 100% | 100% |
| BZIP2 | 1% | 4% | 17% | 46% | 95% | 100% | 100% | 100% | 100% | 100% | 100% |
Анализ представленных данных приводит к выводу, что лучшим архиватором из рассмотренных по результатам тестирования является ZIP, поскольку он наиболее удачно сочетает малые значения обеих ошибок тестов.
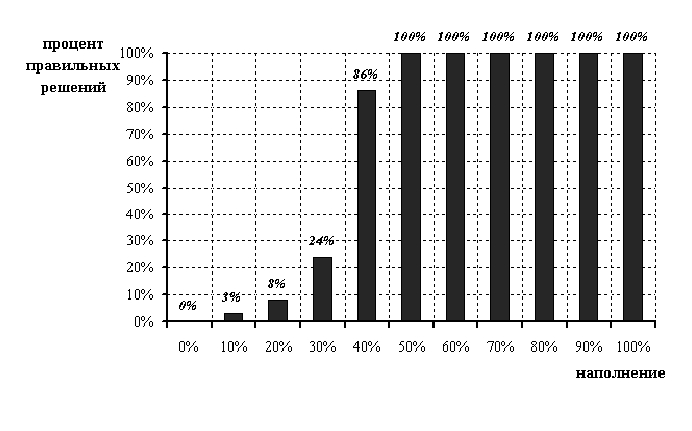
Рис.2 Результаты тестов с архиватором ZIP на "разбросанном" заполнении,
δ = δmin

Рис.3 Результаты тестов с архиватором ZIP на "разбросанном" заполнении,
δ = δmax
Проведено исследование влияния выбора порогового значения на результаты теста. Тест не работает при δ = 0%, при возрастании δ уменьшается ошибка второго рода, но вместе с этим увеличивается ошибка первого рода (см. Рис. 2,3; Табл. 1,2). Такое поведение ошибок в зависимости от δ позволяет выбрать два значения для пороговой величины: минимальное и максимальное. Значение δmin практически не вызывает ошибок 1-го рода (т.е. ложных срабатываний на пустых контейнерах), а значение δmax позволяет достичь "золотую середину" - небольшое значение ошибки второго рода при приемлемой ошибке первого рода.
Эмпирически были подобраны два значения: δmin = 0.8% (см. Рис 2) и δmax = 1.6% (см. Рис 3).
Таким образом, мы видим, что два предлагаемых варианта достаточно эффективно позволяют решать задачу определения скрытой информации.
Предлагаемый метод позволяет в отличие от ранее известных надежно и без участия человека выявлять факт включения данных в изображение формата 24-бит BMP. Ошибка при заполнении контейнера на 50% и более не превышает 3%. Особенностью метода является наличие параметров, позволяющих регулировать чувствительность алгоритма.
[1] Грибунин В.Г., Оков И.Н., Туринцев И.В. Цифровая стегранография. М.: Солон-Пресс, 2002г., 272с.
[2] Ryabko B. Ya., Fionov A.N. Basics of Contemporary Cryptography for IT Practitioners. World Scientific Publishing Co., 2005
[3] Westfeld A., Pfitzmann A. Attacks on Steganographic Systems. Breaking the Steganographic Utilities EzStego,
Jsteg, Steganos and S-Tools - and Some Lessons Learned // Lecture Notes in Computer Science. 2000. Vol. 1768. P. 61-75.
[4] Provos N., Honeyman P. Hide and Seek: An Introduction to Steganography // IEEE Security \& Privacy. 2003. Vol. 5. P. 32-44.
[5] Dabeer O., Sullivan K., Madhow U., Chandrasekaran S., and Manjunath B. S. Detection of hiding in the least
significant bit // In IEEE Trans. on Signal Processing. 2004. Vol. 52. P. 3046-3058.
[6] Fridrich J., Goljan M., and Du R. Reliable Detection of LSB Steganography in Color and Grayscale Images //
Proc. of the ACM Workshop on Multimedia and Security. 2001. P. 27-30.
[7] Mitra S., Roy T., Mazumdar D., Saha A.B. Steganalysis of LSB encoding in uncompressed images by close colour
pair analysis // Indian Institute of Technology at Kanpur Hacker's Workshop. Feb. 2003.