МНОГОКРИТЕРИАЛЬНЫЙ АНАЛИЗ БЕЗВОЗВРАТНЫХ АЛГОРИТМОВ ПОИСКА СИМВОЛЬНОЙ ИНФОРМАЦИИ
(Polycriterion analysis of the non-returnable search algorithms of the symbolical information)
Атакищев О.И., Титенко Е.А., Евсюков В.С., Семенихин Е.А.
Курский государственный технический университет
Курск, e-mail: slava_rec@bk.ru
В современный период развития информационного общества высокие технологии обработки огромных массивов данных приобретают небывалую востребованность. С каждым годом растет число постреляционных систем управления базами данных, с помощью которых решаются задачи мгновенной обработки запросов к базам, содержащим колоссальные объемы информации. Высокоскоростной доступ к сетевым ресурсам также требует вычислительной мощи современных устройств для обработки не только файловой и пакетной информации, но и элементарных блоков информации – битов. В то же время, теория обработки символьной информации способна решать вышеизложенные задачи на более высоком уровне, нежели простая арифметика. Поиск информации, сопоставление с имеющимися данными, выявление зависимости на уровне слов, нечеткий (с высоким значением релевантности) поиск – это задачи теории обработки символьной информации.
В общем виде задачи поиска в теории символьной информации сводятся к выявлению вхождения некоторой последовательности символов (образца) – поисковое слово – в заданную последовательность уже имеющейся информации (текст). В общем случае, и образец и заданный текст состоят из одномерной последовательности символов конечного алфавита, принимаемого заранее. Мощность алфавита меняется в зависимости от потребностей от двух символов, представленных кодами 0 и 1, до всех символов, например, китайского письма, что оказывает существенное влияние на временную сложность поисковых алгоритмов.
В настоящий момент существует обширное множество алгоритмов поиска символьной информации. Большинство из существующих алгоритмов ориентировано на неотступный (безвозвратный) поиск образцов в заданном тексте. Каждый алгоритм эффективен при тех или иных условиях, имеет свою временную зависимость. Но в практической реализации крайне мало алгоритмов ориентировано на параллельную обработку информации.
Довольно полный обзор алгоритмов сопоставления и поиска символьной информации, в который вошли и последние статьи Сандея [1], принадлежит Пирклбауеру [2]. Кроме того, исчерпывающее сравнение эффективности различных алгоритмов по времени и затратам памяти проведено Гоннетом и Бейза-Ейтсом [3].
В качестве критериев выбора алгоритмов поиска символьной информации определим их емкостную сложность, минимальное время предобработки входных данных, наличие побитовых операций, параллелизм вычислительных процессов, способность к нечеткому поиску.
Результатом поиска является обнаружение позиции/позиций вхождения образца в заданный текст или выявление отсутствия его вхождения.
Для унификации процесса поиска образца примем следующие начальные установки для всех рассматриваемых алгоритмом. Пусть заданная строка, в которой осуществляется поиск (Y) – abdeeaabdecdcedebcbadeda, образец (X) – debcbade, все смещения (свдиги) образца производятся с увеличением индекса (вправо) текущих сравниваемых символов образца и заданной последовательности.
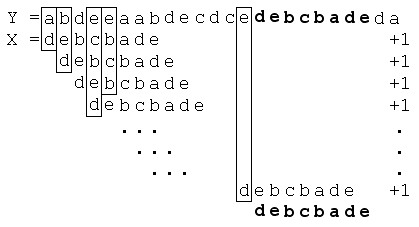
Наиболее простым в реализации и неэффективным на практике является алгоритм прямого (“наивного”) поиска, в котором образец сдвигается относительно заданной последовательности строго слева направо по одному символу, при этом указатель текущего сопоставляемого символа движется как вправо так и влево, сбрасываясь при очередном неудачном сопоставлении (обнаружение отвергающего символа).
Рисунок 1. Пример работы алгоритма прямого ("наивного") поиска
Данный алгоритм не использует предобработку входных данных: образца и заданной последовательности. Количество сравнений фиксировано и составляет величину равную разности длин заданной последовательности и образца, увеличенной на 1, что не является допустимым при большой длине исходной последовательности.
В то же время уменьшение времени поиска достигается путем использования алгоритмов, обрабатывающих и извлекающих полезную информацию на этапе, непосредственно предшествующему поиску, или извлекаемую уже во время поиска.
В основе алгоритма Кнута-Морриса-Пратта [4] лежит идея безвозвратного поиска при возникновении несовпадений. Заданная последовательность в процессе сопоставления с образцом также просматривается слева направо, но при этом, если обнаружен отвергающий символ, величина смещения образца вправо относительно текущей позиции сопоставления с символом заданной последовательности, берется из заранее вычисленной таблицы. Значения элементов таблицы (смещений) вычисляются на предварительном этапе при анализе структуры образца.

Рисунок 2. Пример работы алгоритма Кнута-Морриса-Пратта
Главным недостатком алгоритма Кнута-Морриса-Пратта является его ориентированность на повторяющиеся символы и комбинации символов (префиксы и суффиксы) в структуре образца.
В алгоритме Бойера-Мура [5] заданная последовательность просматривается слева направо, но сопоставление символов образца и последовательности происходит справа налево. Это означает, что сравнение начинается с последнего символа образца и соответствующего ему символа текста. При этом если эти символы не совпадают, то образец смещается вправо на число символов, которое берется как большее из значений, из двух заранее определенных таблиц: таблицы, индексируемой отвергающим символом текста, который вызвал несовпадение (эвристика вхождений), и таблицы, похожей на таблицу, используемую в алгоритме Кнута-Морриса-Пратта (эвристика несовпадений). Идея состоит в том, что в результате сдвига символы образца должны быть равны всем тем символам текста, с которыми они совпадали перед этим, а на месте отвергающего символа должен оказаться другой.

Рисунок 3. Пример работы алгоритма Бойера-Мура
Существует множество модификаций алгоритма Бойера-Мура, нацеленных на уменьшение как временных затрат на предобработку, так и на уменьшение затрат памяти: быстрый поиск, максимальный сдвиг, оптимальное несовпадение (предложены Сандеем [6]), улучшенный алгоритм Бойера-Мура, наименьшая цена (предложены Сандеем и Хьюмом [1]). Однако наибольшую эффективность на основании эмпирических и аналитических исследований показывает алгоритм Бойера-Мура-Хорспула [7], использующий только одну таблицу, индексируемую отвергающими символами текста (эвристику вхождения).
Рассмотрим алгоритм явно ориентированный на нечеткий поиск. Алгоритм поиска СДВИГ-И предложен в 1992 году Манбером и Ву [8]. Используя ранее принятые нами исходную последовательность и образец, будем искать все вхождения восьми шаблонов: d, de, deb, debc, debcb, debcba, debcbad, debcbade. Построим таблицу, которая бы отражала для каждой позиции текста, является ли эта позиция концом каждого из рассматриваемых восьми шаблонов. Для каждой позиции текста получим битовый 8-элементный вектор-массив, в котором k-й бит равен 1, если эта позиция соответствует концу вхождения k-го префикса. В итоге имеем таблицу из m строк и n столбцов, где m – длина образца, n – длина исходной последовательности:

Рисунок 4. Пример работы алгоритма СДВИГ-И
Если в последней строке построенной матрицы обнаруживается 1, то вхождение искомого образца в исходную последовательность найдено. Это означает, что вхождение образца обнаруживается только на последнем шаге построения таблицы, следовательно, основная задача заключается в получении алгоритма быстрого построения таблицы. Алгоритм несложно изменить для осуществления поиска подпоследовательностей с неопределенным значением некоторых символов (нечеткий поиск).
Известны совершенно иные алгоритмы поиска символьной информации, основанные на хэшировании. Однако данные алгоритмы позволяют лишь проверить, входит ли образец в заданную последовательность, но не показывают позицию вхождения. Одним из наиболее эффективных алгоритмов такого рода является алгоритм Карпа-Рабина [9]. Суть данного алгоритма состоит в рассмотрении последовательностей символов не как символьных строк определенной длины, а как их сигнатур, вычисляемых с помощью заранее известных хэш-функций. Это означает, что сравнение двух строк (образца и текущей подпоследовательности заданного текста) сводится к сравнению двух целых чисел, полученных путем применения к ним хэш-функции. При этом необходимо учитывать временные затраты от применения хэш-функции, что должно отражаться на ее выборе и простоте вычисления. Так в большинстве случаев в качестве хэш-функции выбирают операцию деления по модулю некоторого простого числа q, для которого величина 10*q не превышает длины компьютерного слова. Предположим, что образец и заданный текст представлены некоторыми десятичными числами, соответственно 5693 и 8475693653471. В качестве хэш-функции будем использовать деление по модулю 11. Следовательно, нужно найти все подстроки заданного текста, хэш-функции которых имеет значение 6, поскольку 5693 mod 11 = 6.

Рисунок 5. Пример работы алгоритма Карпа-Рабина
Найдены 3 подстроки, удовлетворяющие вышеуказанному условию. Первая подстрока действительно совпадает с образцом, а две другие представляют собой ложное совпадение. Таким образом, если значение хэш-функции некоторой подстроки заданного текста совпадает со значением той же хэш-функции, примененной к образцу, однозначного вывода о равенстве данных строк сделать нельзя. В то же время неравенство хэш-функций явно указывает на однозначное несоответствие подстроки заданной последовательности и образца.
В завершении данного обзора существующих алгоритмов символьного поиска приведем таблицу их сравнительных характеристик:Таблица 1 – Сравнительные характеристики алгоритмов поиска
|
Время на пред. обработку |
Среднее время поиска |
Худшее время поиска |
Затраты памяти |
Нечеткий поиск |
Использова-ние побитовых операций |
Алгоритм |
Нет |
О(2*n) |
O(n*m) |
Нет |
Нет |
Нет |
Алгоритм Кнута-Морриса-Пратта |
O(m) |
O(n+m) |
O(n+m) |
O(m) |
Нет |
Нет |
Алгоритм Боуера-Мура |
O(m+s) |
O(n+m) |
O(n*m) |
O(m+s) |
Нет |
Нет |
Алгоритм Боуера-Мура-Хорспула |
O(m+s) |
O(n+m) |
O(n*m) |
O(m+s) |
Нет |
Нет |
Быстрый поиск |
O(m+s) |
O(n+m) |
O(n*m) |
O(m+s) |
Нет |
Нет |
Алгоритм оптимального несовпадения |
O(m2+s) |
O(n+m) |
O(n*m) |
O(m+s) |
Нет |
Нет |
Алгоритм максимального сдвига |
O(m2+s) |
O(n+m) |
O(n*m) |
O(m+s) |
Нет |
Нет |
Алгоритм |
O(m) |
O(n+m) |
O(n*m) |
Нет |
Да |
Да |
СДВИГ-И |
O(s+m) |
O(n) |
O(n) |
Нет |
Да |
Да |
Некоторые вышеописанные алгоритмы в той или иной мере возможно реализовать с помощью побитовых операций программно-аппаратным или аппаратным способом. Однако данные алгоритмы за исключением алгоритма СДВИГ-И, который для поиска использует нуль-единичную матрицу, слабо ориентированы на параллелизм обработки символьной информации.
Вывод: анализ известных безвозвратных алгоритмов поиска показал, что ни один алгоритм поиска не удовлетворяет всей совокупности определенных критериев. Необходим комбинированный алгоритм безвозвратного поиска, совмещающий лучшие характеристики каждого из рассмотренных. Основу такого комбинированного алгоритма составит идея о реконфигурации структуры входной последовательности.
Библиографический список: