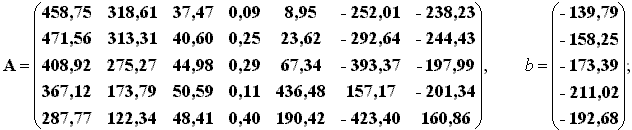
Бурное развитие глобальной сети Internet привело к тому, что ее информационное наполнение стало не только громадно по объему, но и очень разнообразно. Разнообразие информационных ресурсов Сети соответствует широкому спектру информационных потребностей пользователей Internet. Эта ситуация делает проблемы поиска информации в Internet особенно сложными и - одновременно - актуальными.
Большинство универсальных машин поиска (МП) Internet реализует парадигму совпадения запроса из ключевых слов и документа. Этот механизм хорошо работает в традиционных информационно-поисковых системах (ИПС), однако зачастую оказывается малоэффективным при поиске в Internet: в ответ на запрос пользователь получает длинные списки формально релевантных ссылок, из которых его по-настоящему интересуют лишь немногие [Браславский 1998, Лоуренс 2000].
Для повышения эффективности поиска в Internet мы предлагаем использовать стиль текстового документа в качестве дополнительного параметра поиска. Импульсом для наших исследований в этом направлении послужила статья [Karlgren 1994]. Постановка задачи, описание опытного массива документов, методики исследования и первых результатов содержится в наших работах [Браславский 1998, 2000].
Данная работа знакомит со следующими этапами исследования: оптимизацией набора параметров классификации и тестированием процедуры стилистической классификации. Кроме того, излагаются результаты применения процедур канонического дискриминантного анализа (ДА) к опытному массиву и обсуждаются варианты практической реализацими метода.
Пробная классифкация опытного массива документов продемонстрировала эффективность разработанной методики [Браславский 2000]. Следующей задачей стала оптимизация набора параметров классификации.
После вычисления параметров опытного массива была проведена первичная статистическая обработка результатов. Для каждого параметра вычислены минимальные, максимальные, средние значения и стандартные отклонения по каждому стилю; проведены тесты на нормальность распределения, вычислена выборочная матрица корреляции.
На основании анализа полученных результатов из 31 параметра первичного набора (см. [Браславский 2000]) были исключены 10. Основанием для исключения параметра из набора были малая вариабельность средних значений по стилям, большая дисперсия, отличие поведения параметров от предполагаемого a priori. Из оставшихся параметров (21) в процедурах дискриминантного анализа могли быть использованы только 14. Семь параметров не могли быть включены в модель, так как они имеют нулевые дисперсии в одном или нескольких классах (стилях).
Наличие групп взаимно коррелированных параметров указало на возможность сокращения набора параметров классификации.
С помощью последовательных процедур ДА [Клекка 1989] была получена оптимизированная дискриминантная функция семи параметров в виде
s = Ax+b,
где А - матрица коэффициентов; b - вектор констант:
х - вектор параметров документа (х1 - доля глаголов, х2 - доля наречий, х3 - средняя длина слова, х4 - средняя длина предложения, х5 - доля слов общенаучной лексики, х6 - доля слов с научными корнеаффиксами, х7 - доля слов-названий официальных документов).
Отнесение к одному из пяти стилей происходит из условия максимума соответствующей компоненты вектора s (s1 - разговорный, s2 - художественный, s3 - публицистический, s4 - научный, s5 - официально-деловой).
Функция демонстрирует высокое качество классификации документов опытного массива (табл. 1). В целом качество классифкации по семи параметрам не хуже, чем по 14 (при несколько другой структуре ошибок).
Таблица 1
Классификация опытного массива
Художественный
Стиль Разго-
ворный Художест-
венный Публици-
стический Научный Офици-
ально-
деловой Класси-
фицировано
правильно, %
Разговорный
56 5 0 0 0 91,80
9 61 9 0 0 77,22
Публицистический
0 3 58 0 0 95,08
Научный
0 0 2 50 2 92,59
Официально-
деловой
0 0 1 0 49 98,00
Всего
65 69 70 50 51 89,84
Как и следовало ожидать, лучше всего классифицируются документы официально-делового стиля (самого нормированного), а хуже всего - художественного (самого "свободного").
Сокращение набора параметров в два раза (с 14 до 7) практически не снижает вычислительную сложность процедуры: дискриминантная функция линейна, а вычисление двух морфологических параметров так же "затратно", как и десяти. Однако такое сокращение делает процедуру более "обозримой" и интерпретируемой.
Для проверки метода стилистической классификации была смоделирована реалная ситуация. В тестовый массив вошел 71 документ, ссылки на которые выдала ИПС "Яндекс" в ответ на запрос "радикал отношение".
Основная часть документов тестового набора принадлежит научному и публицистическому стилям. Можно предположить, что в целом тестовый массив лучше, чем опытный, отражает стилистическую гамму текстов Internet.
Применение полученной дискриминантной функции к документам тестового массива демонстрирует хорошее качество классификации: для научного стиля - 80%, для публицистического - более 90% корректных случаев (табл. 2). Причем ошибки классификации научных документов (20%) тестового массива - это отнесение к публицистическому стилю гуманитарных научных статей, что неудивительно. Часто эти тексты мало отличаться по стилю от газетных и журнальных публикаций. Кроме того, документы такого рода отсутствовали в обучающей выборке (опытном массиве).
Таблица 2
Классификация тестового массива
Художественный
Стиль Разго-
ворный Художест-
венный Публици-
стический Научный Офици-
ально-
деловой Класси-
фицировано
правильно, %
Разговорный
0 1 0 0 0 0,00
0 1 0 0 0 100,00
Публицистический
0 2 40 0 2 90,91
Научный
0 0 5 20 0 80,00
Всего
0 4 45 20 2 85,92
Применение методов канонического ДА (см. [Клекка 1989]) позволяет выявить геометрическую структуру классов-стилей (рисунок).
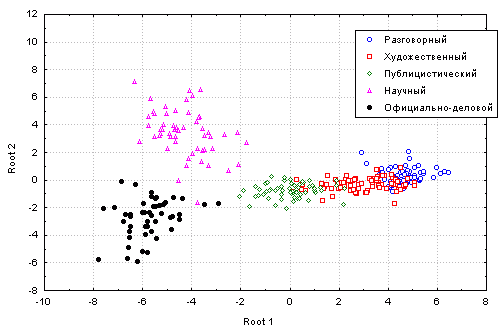
Рисунок. Диаграмма рассеяния документов опытного массива
(Root 1 - первое каноническое направление,
Root 2 - второе каноническое направление)
Первое каноническое направление является линейной комбинацией семи параметров текста (смысл параметров х1, ..., х7 см. выше):
R1 = 18,44·х1 + 22,35·х2 - 1,36·х3 - 0,01·х4 - 37,74·х5 - 15,41·х6 - 31,07·х7 + 5,73
и отражает большую часть стилистического разнообразия документов.
Документы научного и официально-делового стилей на диаграмме рассеяния в координатах канонических направлений образуют изолированные кластеры. Причем их разделение происходит в основном по второму каноническому направлению, за счет формально-семантических параметров (х5, х6, х7).
Хотя четкие границы между стилями отсутствуют, пучки, соответствующие документам публицистического, художественного и разговорного стилей, располагаются последовательно вдоль первого канонического направления.
Анализ этих результатов позволяет на основе первого канонического направления ввести показатель стилистической информативности документа и использовать его в процессе информационного поиска.
С точки зрения пользователя включение в механизмы поиска параметров, связанных со стилем, может разнообразить как выразительные возможности языков запросов, так и формы представления результатов поиска. К новым возможностям относится:
С точки зрения технической реализации процедур классифкации можно рассмотреть несколько вариантов.
Во-первых, стилистическую классификацию можно проводить на этапе индексирования. После этого каждый документ в базе индекса получает дополнительные признаки, связанные с его стилем. Такой вариант наименее требователен к вычислительной эффективности процедуры, однако практически не оставляет "места для маневра" (корректировка коэффициентов, изменение метода классификации, системы стилей и т.п.).
Во-вторых, стилистическую классификацию можно проводить и "на лету", при формировании отклика ИПС (если пользователь задействует эту факультативную возможность). В данном случае требования к вычислительной эффективности более жесткие, но метод сохраняет гибкость "в полном объеме".
Возможен и промежуточный вариант: параметры текста, необходимые для классификации, вычисляются на этапе индексирования, а сама классификация происходит на этапе формирования отклика.
Полученные результаты демонстрируют потенциальную полезность метода в задачах поиска информации в Internet и эффективность его программно-технической реализации.
Одним из направлений дальнейших исследований могла бы стать оптимизация метода классификации. Причем возможно движение как в сторону повышения точности, так и снижения сложности вычисления параметров. Первый путь ведет к использованию нелинейных методов. Второй путь может привести, например, к использованию некоего варианта показателя удобочитаемости (параметр "средняя длина слова" сильно коррелирован с морфологическими параметрами), "усиленного" за счет формально-семантических параметров.
Очевидно, что система пяти функциональных стилей лишь частично подходит для поиска информации в Internet (мало кто ищет чаты и художественные произведениия по ключевым словам). Поэтому для промышленной реализации метода может понадобиться разработка специальной системы жанров документов Internet, которая лучше соответствовала бы задачам информационного поиска.
[Браславский 2000] Браславский П.И. Автоматическая классификация документов Internet по стилям: реализация макета: Доклад V рабочего совещания по электронным публикациям - EL-PUB-2000, Новосибирск, Академгородок, ИВТ СО РАН, 21-23 июня 2000 г.
[Браславский 1998] Браславский П.И. Распознавание стилей речи применительно к информационному поиску: постановка задачи // Математические структуры и моделирование: Сб. научн. тр., Вып. 3. / Под ред. А.К.Гуца. - Омск: Омск. гос. ун-т, 1999. - С. 134-140.
[Клекка 1989] Клекка У.Р. Дискриминантный анализ // Факторный, дискриминантный и кластерный анализ: Пер. с англ. - М.: Финансы и статистика, 1989. - С. 78-138.
[Лоуренс 2000] Лоуренс С. Контекст при поиске в Web //Открытие системы, - 2000. - №12. - С. 62-66.
[Karlgren 1994] Karlgren J., Cutting D. Recognizing Text Genres with Simple Metrics Using Discriminant Analysis // Proc. 15th Int. Conf. on Computational Linguistics (COLING). - Kyoto, 1994. - Vol. 2. - P. 1071-1075.